Kako obrezati optično prebran dokument v Wordu. Primer prenosa skeniranega dokumenta v Word. Vmesnik in razpoložljiva opravila
Dober dan vsem!
Mislim, da tisti uporabniki, ki pogosto opravljajo pisarniško delo (urejanje in priprava dokumentov, skeniranje, pošiljanje ipd.), velikokrat izgubljajo čas z ubadanjem z urejanjem datotek.
Na primer, skeniral sem ducat ali dva listov pogodbe in potem pogledaš: nekateri listi so obrnjeni na glavo (ali na splošno je nekaj listov ekstra) ... Kaj storiti? Lahko znova skenirate (kar večina stori) ali pa dokument zelo hitro uredite s posebnimi orodji. programi.
Pravzaprav v tem članku želim pogledati ta majhen del pisarniškega dela. Mislim, da bo marsikomu uporabno...
Pomagati!
Navodila za skeniranje dokumentov (povezava skenerja z osebnim računalnikom, izbira programske opreme, pridobivanje besedila iz skeniranih ipd. vprašanja) -
Spreminjanje in urejanje dokumentov PDF
1) Kaj je potrebno za delo (izbira programske opreme)
Predvidevam, da že imate dokument PDF (ki ga želite urediti). Zdaj morate izbrati programsko opremo, da jo spremenite. Za preprosto in hitro rešitev problema (na katerem smo se ustavili v tem članku) bo naredil Urejevalnik PDF Movavi.
Urejevalnik PDF Movavi
![]()
Zelo kompakten in priročen program, ki vam omogoča hitro urejanje datotek PDF! Opozoril bi nizko Sistemske zahteve te programske opreme na strojno opremo, zahvaljujoč kateri je mogoče tudi na "šibkih" pisarniški računalniki odprite in uredite datoteke PDF visoka kvaliteta(v barvi z visoka ločljivost).
Posebnosti:
- na voljo so vse osnovne funkcije urejanja: dodajanje/brisanje strani, vrtenje strani za 90-180 stopinj, vstavljanje podpisov, slik, spajanje/deljenje dokumentov, PDF pretvorba v slike (in obratno);
- program se odpre in omogoča spreminjanje velike večine PDF-jev (tudi precej velikih, z visoko ločljivostjo skeniranja, kar je pomembno za pisarno (številni drugi programi lahko preprosto zamrznejo));
- nizke sistemske zahteve;
- intuitiven vmesnik (mimogrede, program je v celoti v ruščini!);
- združljiv z Windows 7, 8, 10 (32/64 bitov).
Morda edino negativno: celotna različica Program stane 600 rubljev. (vendar je na voljo 7 dni za testiranje).
V nadaljevanju članka bom prikazal glavne korake za delo z urejevalnikom PDF Movavi.
2) Odpiranje dokumenta
Ne štejem za namestitev in zagon urejevalnika (so standardni). Če želite odpreti datoteko PDF, kliknite istoimenski gumb v prvem oknu programa. (glej posnetek zaslona spodaj)
Mimogrede, ugotavljam, da program hrani zgodovino prej odprte datoteke, ki vam bo čez čas omogočil hitro iskanje dokumentov, s katerimi pogosto delate.


Datoteka se mora odpreti v urejevalniku. Programski vmesnik je na splošno standarden: vse strani dokumenta so predstavljene na levi strani, sam dokument pa je v sredini.

Kako izgleda odprt dokument v urejevalniku PDF Movavi
Zdaj lahko nadaljujete z urejanjem ...
3) Zasukaj strani 90-180°
In tako nisem slučajno odprl svojega dokumenta: nekaj strani v njem je bilo skeniranih vodoravno, vendar potrebujem vse v navpičnem položaju (pribl. : "pokvarjena" specializirana programska oprema za optični bralnik, ki je priložena gonilnikom, samodejno oblikuje postavitev dokumenta pri shranjevanju kot PDF).
Da ne bi iskali vsake »napačne« strani v običajnem načinu gledanja, priporočam, da greste na pregled vseh strani (za to kliknite gumb, glejte spodnji posnetek).


Zasukaj strani / na klik
Operacije vrtenja strani se izvajajo zelo hitro: dobesedno dva ali trije kliki in vsi listi v mojih dokumentih so postali navpični (glejte primer spodaj).

Za vrnitev v normalen način delo z dokumentom kliknite na gumb na plošči "Nazaj"(glejte posnetek zaslona spodaj).

Upoštevajte, da lahko stran tudi zavrtite v meniju na levi (edina točka: tukaj jih ni zelo priročno "iskati" ...) .

4) Odstranjevanje in vstavljanje strani, slik
Glede izbriši stran- potem je tukaj vse preprosto: najprej morate izbrati stran v meniju na levi, nato z desno miškino tipko kliknite nanjo in v meniju izberite »izbriši« (primer spodaj).
Uporabite lahko tudi tipko Delete.

Kar zadeva vstavljanje novih strani(in slike) v dokument, potem je to malo bolj zanimivo. Najprej morate iti na zavihek.

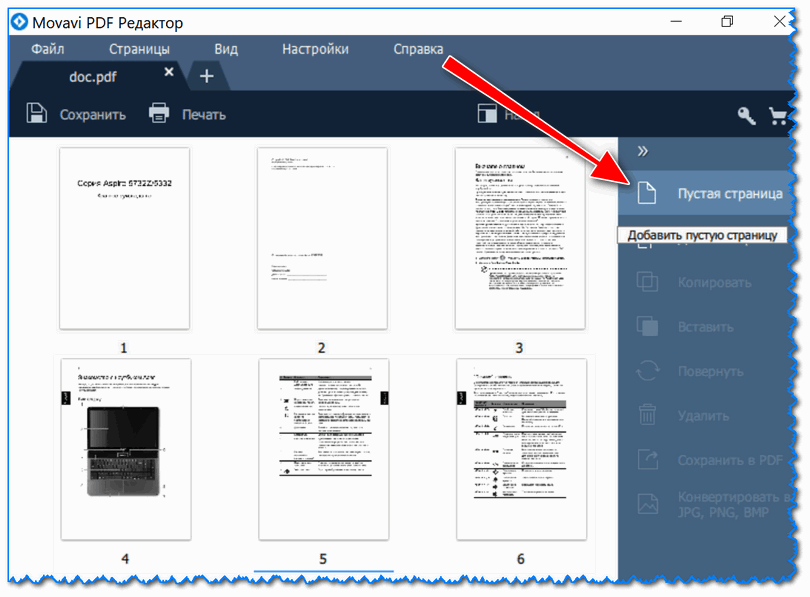
Upoštevajte, da boste imeli na koncu dokumenta eno prazno stran. Oglejte si spodnji posnetek zaslona.

Če to prazno stran povlečete z miško, jo lahko premaknete na želeni del dokumenta. Na primer, vstavil sem ga namesto prve strani (mimogrede, na enak način lahko razvrstite celoten dokument, zamenjate strani in jih premaknete na pravo mesto) .

Za vstavljanje slike (slike): Pojdi do želeno stran, V zgornji meni izberite možnost. Nato se odpre meni Raziskovalec, kjer lahko izberete tistega, ki ga potrebujete.

Na primer, v urejena navodila sem vstavil posnetek zaslona, kako si ogledati značilnosti računalnika (predvsem temperaturo trdega diska). Primer spodaj.

Slika je dodana v dokument
5) Združevanje 2 dokumentov v 1
Tudi dokaj tipično opravilo (še posebej neprijetno, ko je en dokument sestavljen iz 3-4 ali več datotek PDF). Kako jih vse zbrati v eno?
Metoda #1
Najprej morate odpreti prvi dokument (stran) in iti v način pregleda za vse strani (glejte spodnji posnetek zaslona).


Vse strani dodanega dokumenta se prikažejo na koncu odprt dokument(se opravičujem za tavtologijo). Tako pravzaprav dva dokumenta »zlepimo« v enega.

Z doslednim dodajanjem vseh "malih" dokumentov - iz njih boste lahko sestavili enega "velikega", ki ste ga sprva želeli ...
Metoda št. 2
Ta možnost je preprostejša. Po zagonu programa samo kliknite na gumb (v začetnem oknu na desni).

Mimogrede!
Če se vaš dokument PDF izkaže za prevelik (in to se občasno tudi zgodi), ga lahko stisnete. V enem od prejšnjih člankov sem dal več možnosti, priporočam -
To je vse za zdaj. Dodatki so dobrodošli...
Program za optično prepoznavanje besedila. ABBYY FineReader lahko prepozna besedilo iz skeniranih papirnatih dokumentov, datotek PDF in dokumentov, posnetih z digitalnim fotoaparatom. Besedilne dokumente, ki jih program prepozna, je mogoče nadalje urejati z uporabo Microsoftove aplikacije Pisarna. Po potrebi se med prepoznavanjem besedila ohrani celotna struktura oblikovanja dokumenta. FineReader deluje z vsemi priljubljenimi modeli sodobnih skenerjev in večnamenske naprave(večnamenska naprava). Če mora uporabnik optično prebrati in prepoznati veliko število strani besedila, potem program ponuja poseben način za delo avtomatski skenerji(skener z avtomatskim podajalnikom papirja). Program lahko prepozna besedilo v datotekah naslednjih formatov: PDF, BMP, PCX, DCX, JPEG, JPEG 2000, TIFF, PNG, DjVu; po potrebi bodo digitalne slike obdelane za izboljšanje kakovosti optičnega prepoznavanja besedila (slika lahko obrežete in očistite nepotrebnih elementov, odpravite netočnosti, popačenje linij, zavrtite ali zrcalite).Program je celovita aplikacija za delo z besedilnimi dokumenti. Njegov glavni namen je optično prepoznavanje znakov. Ustvarjalec programa je rusko podjetje ABBYY Software (vodja v svetu na področju sistemov za prepoznavanje). Aplikacija hitro in natančno prevede skenirane dokumente v format, ki ga je mogoče urejati, pri čemer ohrani vse podrobnosti izvirnega vira. FineReader lahko prepozna datoteke PDF, digitalne fotografije in papirnate dokumente. Program natančno reproducira videz izvirnega vira, podpira prepoznavanje besedila v 186 jezikih in omogoča neposreden izvoz v aplikacije Microsoft Office.
Z uporabo aplikacije so možna opravila, kot so: ustvarjanje in urejanje elektronskih dokumentov na podlagi papirnih virov, prevajanje dokumentov slabe kakovosti v obliko, ki jo je mogoče urejati, obdelava dokumentov s kompleksno vsebinsko strukturo, vključno s tabelami, ilustracijami, diagrami itd., iskanje in urejanje besedila. se rešujejo v poljubnih oblikah. Po mnenju večine strokovnjakov je program najboljši na svojem področju.
Če govorimo o praksi uporabe tega programa v RuNetu, potem mnogi uporabniki že dolgo poznajo ta program Fine Reader (ruski prevod imena), katerega glavni namen je izvesti tako imenovano optično prepoznavanje besedila. Preprosto povedano, s tem programom lahko vsako besedilo, natisnjeno na papirju, pretvorimo v enega od elektronskih formatov. Najnovejša različica program ni samo posodobljen in več uporabniku prijazen vmesnik, temveč tudi izboljšano funkcionalnost.
Pravzaprav lahko vsa osnovna dejanja izvedemo z enim klikom miške, s katerim ob zagonu programa izberemo eno izmed ponujenih dejanj. Med njimi so možnost skeniranja dokumentov v format .doc, pretvorba fotografij, skeniranje v Excel, shranjevanje slik in njihovo skeniranje, prepoznavanje slik itd. Da bi izboljšali uporabnost programa, Delovni prostor je bil povečan in gumbi, ki sprožijo to ali ono dejanje, so zdaj na stranski vrstici.
Da ne bi zmedli uporabnika, so privzeto vse datoteke, ki jih odpre, samodejno prepoznane. Če je potrebno, lahko izkušen uporabnik temeljito prilagodi funkcionalnost FineReader. In delo s slikami je bilo zaradi novega dialoga zelo poenostavljeno. Uporaba aplikacije vam omogoča prepoznavanje dokumentov, napisanih v več kot enem jeziku, pretvorbo datotek PDF, prepoznavanje črtnih kod in izvajanje morfoloških iskanj. In čeprav to še zdaleč ni popoln seznam njegovih zmogljivosti, lahko samo to spodbudi mnoge uporabnike, da trajno namestijo Fine Reader in ga uporabljajo po potrebi.
In če povzamemo zgoraj navedeno, lahko na kratko opišemo tole: funkcionalnost: Ta program se uporablja za optično prepoznavanje različnih besedilnih dokumentov. Pri prepoznavanju besedila program ohrani prvotno oblikovanje in zasnovo dokumenta (barvno besedilo, besedilo na ozadju slik, različni slogi pisav, oblivanje besedila okoli slik, tabel itd.). FineReader lahko dela s skeniranimi papirnatimi dokumenti (deluje s skoraj vsemi priljubljenimi modeli optičnih bralnikov in multifunkcijskih naprav), z dokumenti, posnetimi z digitalnimi kamerami, ter prepozna besedilo in grafiko iz datotek PDF. Prav tako izvozi rezultate optičnega prepoznavanja besedila v popular pisarniške aplikacije: Word, Excel, PowerPoint, Lotus Word Pro, Corel WordPerfect, OpenOffice. Prepoznano besedilo lahko shranite v različnih formatih: PDF, PDF/A, DOCX, XLSX, RTF, DOC, XLS, CSV, TXT, HTML, Unicode TXT, Word ML, LIT, DBF.
Programska oprema OCR vam omogoča pretvorbo fotografiranih ali skeniranih dokumentov neposredno v stavke.
Dejstvo je, da je besedilo na sliki predstavljeno v obliki rastra, niza pik. Omenjena programska oprema nabor pik pretvori v polno besedilo, ki je na voljo za urejanje in shranjevanje.
Prepoznavanje črk je zasnovano za optimizacijo procesa digitalizacije tiskanih ali ročno napisanih knjig in dokumentov.
Ta metoda digitalizacije je veliko hitrejša od hitrosti ročnega tipkanja s slike. Pogosto se uporablja pri digitalizaciji knjižnic in arhivov. Nato bomo razmislili o petih najboljših predstavnikih družine podobnih programov.
ABBYY FineReader 10
FineReader je nesporen vodja med vsemi programi, ki prepoznajo besedilo v slikah. Zlasti ni programske opreme, ki bi jasneje obdelala cirilico. Na splošno ima FineReader 179 jezikov, besedilo v katerih je izjemno uspešno prepoznano.
Edina stvar, ki lahko razočara uporabnike, je, da je program plačan. Razdeljeno samo brezplačno preizkusna različica za 15 dni. V tem obdobju je dovoljeno skeniranje 50 strani.
Nato boste morali plačati za uporabo programa. FineReader zlahka »poje« več ali manj visokokakovostna slika. Vir je popolnoma nepomemben. Naj bo to fotografija, skenirana stran ali katera koli slika s črkami.
Prednosti:
- natančno prepoznavanje;
- ogromno bralnih jezikov;
- toleranca do kakovosti izvorne slike.
Napaka:
- preizkusna različica za 15 dni.
OCR CuneiForm
Brezplačna programska oprema za branje besedilne informacije iz slik. Natančnost prepoznave je za red velikosti manjša kot pri prejšnjem obravnavanem programu. Toda kako za brezplačen pripomoček, je funkcionalnost še vedno odlična.
zanimivo! CuneiForm prepozna bloke besedila, grafike in celo različne tabele. Poleg tega je mogoče brati tudi nečrtane tabele.
Za zagotavljanje točnosti so v proces prepoznavanja povezani posebni slovarji, ki dopolnjujejo besedišče iz skeniranih dokumentov.
Prednosti:
- brezplačna distribucija;
- s pomočjo slovarjev preverjajo pravilnost besedila;
- skeniranje besedila iz fotokopij slabe kakovosti.
Napake:
- relativno nizka natančnost;
- majhno število podprtih jezikov.
WinScan2PDF
Ni niti polnopravni program, ampak pripomoček. Namestitev ni potrebna, izvršljiva datoteka pa tehta le nekaj kilobajtov. Postopek prepoznave je izjemno hiter, čeprav se nastali dokumenti shranjujejo izključno v formatu PDF.
Pravzaprav se celoten postopek izvede s pritiskom na tri gumbe: izbiro vira, cilja in pravzaprav zagon programa.
Pripomoček je zasnovan za hitro paketno obdelavo številnih datotek. Za udobje uporabnikov je na voljo velik jezikovni paket vmesnika.
Prednosti:
- prenosljivost;
- hitro delo;
- Enostavnost uporabe.
Napake:
- najmanjša velikost;
- edini format izhodne datoteke.
SimpleOCR
Odličen majhen program za prepoznavanje besedil iz slik. Podpira celo branje rokopisov. Težava je v tem, da ruščina ni vključena niti v jezikovni paket vmesnika niti na seznam jezikov, podprtih za prepoznavanje.
Če pa morate skenirati angleščino, dansko ali francoščino, potem ne boste našli boljše brezplačne možnosti.
V svojem obsegu program zagotavlja natančno dekodiranje pisave, odstranjevanje šuma in ekstrakcijo grafične slike. Poleg tega ima vgrajen programski vmesnik urejevalnik besedil, skoraj enak WordPadu, kar znatno poveča uporabnost programa.
Prednosti:
- natančno prepoznavanje besedila;
- priročen urejevalnik besedil;
- odstranjevanje šuma iz slike.
Napake:
- popolna odsotnost ruskega jezika.
Freemore OCR
Program omogoča hitro ekstrahiranje besedila in grafike iz slik. Programska oprema podpira delo z več skenerji brez izgube zmogljivosti. Ekstrahirano besedilo lahko shranite v besedilni dokument ali format dokumenta MS Office.
Poleg tega je na voljo funkcija prepoznavanja več strani.
Freemore OCR se distribuira brezplačno, vendar je vmesnik samo v angleščini. Toda ta okoliščina nikakor ne vpliva na enostavnost uporabe, saj so kontrole organizirane na intuitiven način.
Prednosti:
- brezplačna distribucija;
- sposobnost dela z več skenerji;
- natančnost prepoznave je spodobna.
Napake
- Pomanjkanje ruskega jezika v vmesniku;
- Potreba po prenosu ruskega jezikovnega paketa za prepoznavanje.
Če ste izbrali hiter način pisanja teoretičnega poglavja, o katerem smo govorili v odstavku 2.1., brez skeniranja dokumentov najverjetneje ne boste mogli. V nasprotnem primeru lahko to točko preskočite in si začnete zapisovati gradivo, ki ga najdete v knjižnici.
Preden začnete skenirati, se morate odločiti, kaj točno želite uporabiti pri pisanju svojega dela. Če želite to narediti, morate najprej pregledati razpoložljivo literaturo in s svinčnikom označiti potrebne točke.
Ko sem prvič skeniral članek iz revije za svojo prvo nalogo, se mi je zdela naloga neverjetno težka. Kot rezultat večurnega dela s skenerjem in FineReaderjem je bil rezultat neumnost, ki je ni bilo mogoče urejati. Na koncu sem moral vse tipkati ročno. Da se vam to ne bi zgodilo, si podrobneje oglejmo vse tehnične vidike skeniranja.
Za skeniranje bomo seveda potrebovali skener. Ni ti ga treba kupiti. Lahko si na primer za nekaj časa sposodite nekaj od prijatelja. Uporabljam skener CanoScan Lide 60. Čeprav ni najbolj nov model, vendar mi je ta kompaktna, hitra in enostavna "naprava" zelo všeč. Če si izposodite skener, morate za njegovo delovanje najprej namestiti gonilnik. Gonilnike in navodila za namestitev lahko vedno najdete na namestitveni disk, ki je priložen napravi ali pa ga lahko prenesete s spletne strani proizvajalca. Po namestitvi gonilnika povežite optični bralnik z računalnikom s povezovalnim kablom. Zdaj lahko začnete neposredno skenirati.
Toda najprej malo teorije. Vedeti morate, da je postopek skeniranja sestavljen iz dveh stopenj:
1. Neposredno skeniranje dokumenta. Na tej stopnji skener posname fotografijo površine dokumenta, ki ga skenira, in shrani sliko v računalnik kot običajno datoteko .jpg .gif ali v drugem formatu;
2. Prepoznavanje dokumentov. To je postopek pretvorbe besedila iz slike, posnete s skenerjem, v običajni test, ki ga lahko nato shranite v Word in uredite. Prepoznavanje poteka brez sodelovanja optičnega bralnika z uporabo posebnega programa (najbolj priljubljen je Adobe FineReader). Na ta način lahko najprej skenirate več listov besedila in jih shranite kot sliko, preden jih pretvorite v besedilo.
Torej, začnimo prva faza - skeniranje:
– zaženite gonilnik optičnega bralnika: Start - Vsi programi - Canon - ScanGear(Navajam ime gonilnika za svoj skener). Prikaže se okno gonilnika:
– odprite pokrov optičnega bralnika in postavite knjigo, revijo ali njen izvod z besedilom obrnjenim navzdol, čim bolj enakomerno glede na robove delovne površine optičnega bralnika:
Pri tem je zelo pomembno zagotoviti, da pokrov optičnega bralnika čim tesneje pritiska na skenirani dokument in preprečuje, da bi zunanja svetloba dosegla delovno površino optičnega bralnika, ki je v stiku z dokumentom;
- naredimo to potrebne nastavitve v gonilniku optičnega bralnika. Prvi korak je nastavitev ločljivosti, pri kateri bo dokument skeniran. Ločljivost je indikator, ki določa stopnjo podrobnosti predmeta pri skeniranju in je določena v pikah na palec (dpi ali dpi). Višja kot je ločljivost, boljša je kakovost slike. Toda pri skeniranju besedilnih dokumentov nima smisla nastavljati največje ločljivosti, saj bo to neuporabno. Poleg tega skeniranje pri višjih ločljivostih traja dlje. Priporočam nastavitev ločljivosti med 400-500 dpi. S to nastavitvijo so slike dovolj kakovostne za dobro razpoznavnost, sam postopek skeniranja pa ne traja veliko časa. Predlagam, da si ogledate posnetek zaslona nastavitev mojega tiskalnika:
 |
Najprej morate iti na "Napredni način". Vir bo vedno "tablica"(ploski skener). Bolje je nastaviti barvni način "Črno in belo", ker za optično branje besedila ne potrebujemo barv, kar bo zmanjšalo velikost izhodnih slik. Resolucija, kot sem rekel, bi morala biti določena 400 dpi. Velikost izhodne slike – zahtevana “A4”. Zdaj lahko varno pritisnete gumb "Skeniraj". Moj skener je zasnovan tako, da najprej shrani skenirane slike notranji pomnilnik, in šele ob zapiranju okna gonilnika ponudi njihovo shranjevanje v računalnik. Vse kar moram storiti je, da navedem lokacijo, kamor bodo shranjeni rezultati dela.
Na koncu bi morali imeti datoteke te vrste:

Ko takšno sliko povečate, mora biti besedilo jasno vidno.
Druga faza – priznanje prejete slike in jih pretvorite v besedilo. Kot sem že rekel, bo to zahtevalo poseben program - FineReader. Prenesite program s te povezave (32MB). Arhivsko geslo – spletna stran. Različica, ki jo predlagam, ne zahteva namestitve (prenosna). V programski mapi bo veliko različnih datotek, vendar potrebujete samo eno - FineReader.exe. Dvojni klik na to datoteko bo zagnal program v vašem računalniku.
Ta različica programa je precej stara. Z njim sem naredil vse spodnje posnetke zaslona. Če ta različica FineReader ti ne gre - izberi novejšega.
Okno FineReader ima naslednjo obliko:

Ko nastavite jezik, v katerem so bili natisnjeni dokumenti, ki ste jih predhodno skenirali, lahko začnete s prepoznavanjem. Če besedilo vsebuje dva jezika hkrati (na primer rusko in angleško), ustrezno namestite.
Če želite začeti prepoznavanje, kliknite na puščico desno od prvega gumba Skeniraj- in potem - Odpri sliko:

Odpre se okno za izbiro slike. Odprite mapo, v katero ste shranili optično prebrane slike, kliknite CTRL+A(angleščina) na tipkovnici in pritisnite gumb Odprto.

Po tem na levi v oknu FineReader Prikazale se bodo sličice dodanih datotek, v sredini - vklopljeno ta trenutek izbrana skica je povečana, spodaj je še večja povečava, desno pa rezultat prepoznave:

Na primer, posnel sem samo dve sliki. Prvi izmed njih je označen na zgornjem posnetku zaslona; zdaj ga lahko prepoznamo. Kot lahko vidite, je bila slika skenirana navpično; da bi prepoznali besedilo, je treba sliko najprej obrniti za 90 stopinj. Če želite to narediti, uporabite gumba in . Naslednji korak je, da programu poveste, kateri del slike mora prepoznati, in tudi nastavite vrsto podatkov, ki naj bodo izpisani: besedilo, tabela ali slika. Za to obstajajo gumbi: . Na primer, če morate označiti besedilni blok, z levo tipko miške kliknite , nato z levo miškino tipko kliknite v zgornji levi kot besedilnega bloka in, medtem ko držite levi gumb, povlecite v spodnji desni kot. Na primer, v celoti sem pripravil eno sliko za prepoznavanje:

Kot lahko vidite, so vsi besedilni bloki v zgornjem primeru označeni z zeleno, slike pa rdeče. Na enak način so pripravljene tudi tabele za razpoznavanje. Temu je namenjen gumb. Za pomik na naslednjo fotografijo z levim klikom na njeno sličico na levi. Na ta način so vse slike, pridobljene s skeniranjem, pripravljene za razpoznavo. Ko je priprava slik končana, jih morate vse izbrati. Če želite to narediti, z levo tipko miške kliknite prazen prostor na plošči s sličicami (imenuje se Plastična vrečka) in pritisnite Ctrl+A(angleščina) na tipkovnici. Nato kliknite na gumb in počakajte, da FineReader pretvori slike v besedilo. Po tem lahko nastalo besedilo shranite v Word z gumbom, po kliku na katerega se odpre okno. V njem morate izbrati obliko shranjevanja - Microsoft Word in potrdite polje, da shranite vse strani:
Po pritisku na gumb v redu bo program ustvaril Wordov dokument in vanjo vstavi besedilo s prepoznanih strani v vrstnem redu, v katerem se nahajajo na plošči s sličicami (Paket). Prejeti dokument takoj shranite v mapo v strukturo datoteke diplomsko delo in lahko začnete urejati. Kako se to naredi, je opisano v mojem brezplačen tečaj.
In še zadnja točka. Če ste skenirali časopis ali revijo, je tam besedilo pogosto podano v obliki stolpcev (kot v zgornjem primeru). Te stolpce v Wordu je treba pretvoriti v enega. Izberite besedilo v stolpcih in zaženite ukaz: Oblika – Stolpci – Ena – OK. Šele po tem lahko nastavite pokončno usmerjenost v nastavitvah strani, oblazinjenje robov, pisavo itd.
Kako skenirati dokument in ga prepoznati v MS Wordu
Shranjevanje skeniranih dokumentov na trdi disk vašega računalnika ali zunanjo napravo za shranjevanje je priročno in varno. Vendar, kako narediti spremembe na straneh, ki so običajno predstavljene kot slika? Potrebovali bomo posebni programi, katerega namestitev in upravljanje bomo opisali v nadaljevanju.
Kako skenirati dokument pred urejanjem?
Da bi v prihodnosti uspešno manipulirali z datoteko, je pomembno, da jo pravilno pretvorite v format "slike" in upoštevate več preprostih, a uporabnih odtenkov v samem procesu. Za to:
- Zgladite vse gube in gube, da se ne bodo pojavile na skeniranju in da ne bodo povzročale težav pri prepoznavanju črk.
- Za lažjo uporabo shranite datoteko v formatu PDF, JPG ali TIFF.
- Dokument PDF je mogoče odpreti in urejati program Adobe Acrobat (ali kateri koli drug, zasnovan za podobne namene).
- Pojdite na spletno mesto podjetja, ki je ustvarilo optični bralnik, ali poiščite lastniški program na priloženem disku (pogosto imajo znane blagovne znamke svoje aplikacije za spreminjanje skeniranih strani).
- Za kasnejšo uporabo datoteke v MS Office 2003 ali 2007 namestite Microsoftov pripomoček Skeniranje pisarniških dokumentov. Samodejno pretvori optično prebrano datoteko in jo pretvori neposredno v besedilo (program ne deluje z novejšimi različicami Officea).
- Priporočljivo je črno-belo skeniranje namesto barvnega – tako je lažje analizirati besedilo.
- Format TIFF je najbolje uporabiti za pretvornike OCR, torej programe, ki izvajajo optično prepoznavanje.
Kako urediti optično prebran dokument - delo s pripomočki OCR
Načelo metode optičnega prepoznavanja znakov je, da preberete znake na papirju in jih nato primerjate z elementi iz lastne baze podatkov. Na ta način se trdna slika pretvori v besedilo, ki ga je mogoče urejati. Živa primera programov, ki se spopadajo s to nalogo, sta Adobe Acrobat in Evernote. Če želite popraviti obstoječe skeniranje, ga preprosto odprite z eno od teh aplikacij, celoten nadaljnji postopek se bo zgodil samodejno. Ko program konča prepoznavanje, bo uporabnika pozval, naj dokument shrani v enega od razpoložljivih formatov.


Kako urediti optično prebran dokument PDF
Če je skenirani dokument shranjen v PDF datoteka, ga lahko preprosto uredimo v programu Acrobat DC. Za to:
- odprite meni “Orodja” -> “Uredi PDF”;
- program začne postopek urejanja in v zgornjem desnem kotu prikaže meni z namigi;
- s klikom nanj in izbiro »Možnosti« lahko določite jezik prepoznavanja;
- Če želite narediti spremembe, preprosto kliknite katero koli vrstico dokumenta;
- dokument, odprt za urejanje prek OCR, spremlja posebna plošča z nastavitvami na desni strani zaslona;
- V razdelku »Nastavitve« je poleg jezika priročno izbrati tudi prikazano pisavo in označiti strani, ki jih je treba urediti (vse ali eno naenkrat).


Na svetovnem spletu je dostopna alternativa programom za pretvorbo, ki jih je mogoče namestiti. To so spletni OCR-ji, ki lahko preprosto pretvorijo nastalo sliko v kateri koli besedilni format. Spletna stran pdfonline.com vam na primer omogoča, da iz skeniranega dokumenta PDF v nekaj minutah ustvarite običajno datoteko MS Word.
