Kako izrezati skenirani dokument u Wordu. Primjer kako prenijeti skenirani dokument u Word. Sučelje i dostupni zadaci
Dobar dan svima!
Mislim da oni korisnici koji često rade uredske poslove (uređivanje i priprema dokumenata, skeniranje, slanje itd.) često gube vrijeme petljajući oko toga da datoteke budu vidljive.
Na primjer, skenirao sam desetak ili dva listova ugovora, a onda vidite: neki listovi su naopako (ili općenito neki list je višak)... Što učiniti? Možete ponovo skenirati (što će većina učiniti) ili možete vrlo brzo urediti dokument pomoću posebnih alata. programa.
Zapravo, u ovom članku želim se osvrnuti na ovaj mali dio uredskog posla. Mislim da bi mnogima moglo biti od koristi...
Pomoći!
Upute za skeniranje dokumenata (spajanje skenera na računalo, odabir softvera, dobivanje teksta iz skenova itd. pitanja) -
Izmjena i uređivanje PDF dokumenata
1) Što je potrebno za rad (odabir softvera)
Pretpostavit ću da već imate PDF dokument (koji želite urediti). Sada trebate odabrati softver da biste ga promijenili. Za jednostavno i brzo rješenje problema (na kojem smo stali u ovom članku) učinit će Movavi PDF Editor.
Movavi PDF Editor
![]()
Vrlo kompaktan i prikladan program, što vam omogućuje brzo uređivanje PDF datoteka! Napomenuo bih nizak Zahtjevi sustava ovog softvera na hardver, zahvaljujući čemu je moguće čak i na "slabim" uredska računala otvarati i uređivati PDF datoteke visoka kvaliteta(u boji s visoka rezolucija).
Osobitosti:
- postoje sve osnovne funkcije za uređivanje: dodavanje/brisanje stranica, rotiranje stranica 90-180 stupnjeva, umetanje potpisa, slika, spajanje/dijeljenje dokumenata, PDF pretvorba u slike (i obrnuto);
- program se otvara i omogućuje vam promjenu velike većine PDF-ova (čak i prilično velikih, s visokom rezolucijom skeniranja, što je važno za ured (mnogi drugi programi mogu jednostavno zamrznuti));
- niski zahtjevi sustava;
- intuitivno sučelje (usput, program je u potpunosti na ruskom!);
- kompatibilan s Windows 7, 8, 10 (32/64 bita).
Možda jedino negativno: Puna verzija Program košta 600 rubalja. (međutim, ima 7 dana za testiranje).
U nastavku članka pokazat ću glavne korake za rad s Movavi PDF editorom.
2) Otvaranje dokumenta
Ne uzimam u obzir instaliranje i pokretanje editora (oni su standardni). Da biste otvorili PDF datoteku, samo kliknite na istoimeni gumb u prvom prozoru programa. (pogledajte snimak zaslona u nastavku)
Usput, napominjem da program čuva povijest ranije otvorene datoteke, koji će vam s vremenom omogućiti brzo pronalaženje dokumenata s kojima često radite.


Datoteka bi se trebala otvoriti u editoru. Sučelje programa općenito je standardno: sve stranice dokumenta prikazane su s lijeve strane, a sam dokument je u sredini.

Kako izgleda otvoreni dokument u Movavi PDF Editoru
Sada možete prijeći na uređivanje...
3) Rotirajte stranice 90-180°
I tako, nisam slučajno otvorio svoj dokument: neke su stranice u njemu skenirane vodoravno, ali sve trebam u okomitom položaju (cca. : "krivi" specijalizirani softver za skener koji dolazi s upravljačkim programima automatski formatira izgled dokumenta prilikom spremanja kao PDF).
Kako ne biste tražili svaku "pogrešnu" stranicu u normalnom načinu pregledavanja, preporučujem da odete na pregled svih stranica (da biste to učinili, kliknite na gumb, pogledajte snimak zaslona u nastavku).


Rotiranje stranica / moguće kliknuti
Operacije rotacije stranica izvode se vrlo brzo: doslovno dva ili tri klika i svi su listovi u mojim dokumentima postali okomiti (vidi primjer u nastavku).

Za povratak na normalni mod rad s dokumentom, kliknite na gumb na ploči "Leđa"(pogledajte snimak zaslona u nastavku).

Imajte na umu da stranicu možete rotirati i u izborniku s lijeve strane (jedina stvar: nije baš zgodno "tražiti" ih ovdje...) .

4) Uklanjanje i umetanje stranica, slika
O izbrisati stranicu- onda je ovdje sve jednostavno: prvo trebate odabrati stranicu u izborniku s lijeve strane, zatim desnom tipkom miša kliknite na nju i odaberite "izbriši" u izborniku (primjer u nastavku).
Također možete koristiti tipku Delete.

Što se tiče umetanje novih stranica(i slike) u dokument, onda je ovo malo zanimljivije. Prvo morate otići na karticu.

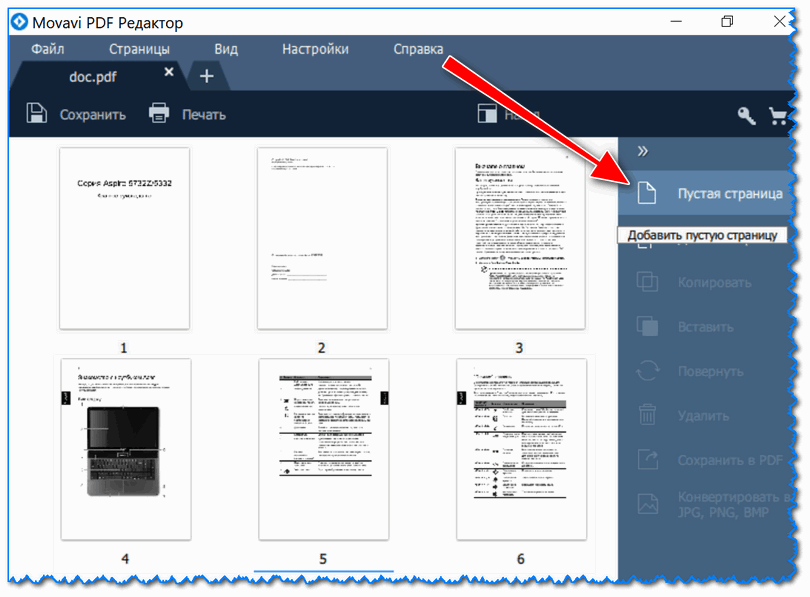
Imajte na umu da ćete na kraju dokumenta imati jednu praznu stranicu. Pogledajte snimak zaslona u nastavku.

Povlačenjem ove prazne stranice mišem možete je premjestiti na željeni dio dokumenta. Na primjer, umetnuo sam ga umjesto prve stranice (usput, možete sortirati cijeli dokument na isti način, mijenjajući stranice i premještajući ih na pravo mjesto) .

Za umetanje slike (slike): ići željenu stranicu, V gornji izbornik odaberite opciju. Zatim će se otvoriti izbornik Explorer, gdje možete odabrati onaj koji vam je potreban.

Na primjer, u uređenu sam uputu ubacio snimku zaslona kako pregledati karakteristike računala (konkretno temperaturu HDD-a). Primjer ispod.

Slika se dodaje u dokument
5) Kombiniranje 2 dokumenta u 1
Također prilično tipičan zadatak (osobito neugodan kada se jedan dokument sastoji od 3-4 ili više PDF datoteka). Kako ih sve skupiti u jedan?
Metoda #1
Najprije trebate otvoriti prvi dokument (stranicu) i otići u način pregleda za sve stranice (pogledajte snimak zaslona u nastavku).


Sve stranice dodanog dokumenta pojavit će se na kraju otvoreni dokument(oprostite na tautologiji). Dakle, mi zapravo “lijepimo” dva dokumenta u jedan.

Dosljednim dodavanjem svih “malih” dokumenata - od njih ćete moći sastaviti jedan “veliki” koji ste željeli na početku...
Metoda #2
Ova opcija je jednostavnija. Nakon pokretanja programa samo kliknite na gumb (na početnom prozoru s desne strane).

Usput!
Ako se vaš PDF dokument pokaže prevelikim (a i to se s vremena na vrijeme događa), možete ga komprimirati. U jednom od mojih prethodnih članaka dao sam nekoliko opcija, preporučujem -
To je sve za sada. Dodaci su dobrodošli...
Program za optičko prepoznavanje teksta. ABBYY FineReader može prepoznati tekst iz skeniranih papirnatih dokumenata, PDF datoteka i dokumenata snimljenih digitalnom kamerom. Tekstualni dokumenti koje program prepoznaje mogu se dalje uređivati korištenjem Microsoftove aplikacije Ured. Ako je potrebno, cjelokupna struktura dizajna dokumenta bit će sačuvana tijekom prepoznavanja teksta. FineReader radi sa svim popularnim modelima modernih skenera i multifunkcionalni uređaji(MFP). Ako korisnik treba skenirati i prepoznati veliki broj stranica teksta, tada program nudi poseban način rada automatski skeneri(skener s automatskim ulagačem papira). Program može prepoznati tekst u datotekama sljedećih formata: PDF, BMP, PCX, DCX, JPEG, JPEG 2000, TIFF, PNG, DjVu; po potrebi će se digitalne slike obraditi radi poboljšanja kvalitete optičkog prepoznavanja teksta (slika može se izrezati i očistiti od nepotrebnih elemenata, ukloniti netočnosti, izobličenje linija, rotirati ili zrcaliti).Program je sveobuhvatna aplikacija za rad s tekstualnim dokumentima. Njegova glavna svrha je optičko prepoznavanje znakova. Tvorac programa je ruska tvrtka ABBYY Software (svjetski lider u području sustava za prepoznavanje). Aplikacija brzo i točno prevodi skenirane dokumente u format koji se može uređivati, čuvajući sve detalje izvornog izvora. FineReader može prepoznati PDF datoteke, digitalne fotografije i papirnate dokumente. Program točno reproducira izgled izvornog izvora, podržava prepoznavanje teksta na 186 jezika i omogućuje izravan izvoz u Microsoft Office aplikacije.
Korištenjem aplikacije zadaci kao što su: izrada i uređivanje elektroničkih dokumenata na temelju papirnatih izvora, prevođenje dokumenata loše kvalitete u format koji se može uređivati, obrada dokumenata složene strukture sadržaja, uključujući tablice, ilustracije, dijagrame itd., pretraživanje i uređivanje teksta rješavaju se u svim formatima. Prema većini stručnjaka, program je najbolji u svom području.
Ako govorimo o praksi korištenja ovog programa na RuNetu, tada mnogi korisnici već dugo poznaju ovaj program Fine Reader (ruski prijevod naziva), čija je glavna svrha izvršiti takozvano optičko prepoznavanje teksta. Pojednostavljeno rečeno, pomoću ovog programa svaki tekst ispisan na papiru može se pretvoriti u neki od elektroničkih formata. Najnovija verzija program nije samo ažuriran i više korisničko sučelje, ali i poboljšana funkcionalnost.
Naime, sve osnovne radnje moguće je izvršiti jednim klikom miša, kojim se odabire jedna od ponuđenih radnji pri pokretanju programa. Među njima su mogućnost skeniranja dokumenata u .doc format, pretvaranje fotografija, skeniranje u Excel, spremanje slika i njihovo skeniranje, prepoznavanje slika itd. Kako bi se poboljšala upotrebljivost programa, Radni prostor je povećan, a gumbi koji pokreću ovu ili onu akciju sada se nalaze na bočnoj traci.
Kako ne bi zbunili korisnika, prema zadanim postavkama sve datoteke koje otvori se automatski prepoznaju. Ako je potrebno, iskusni korisnik može izvršiti duboke prilagodbe funkcionalnosti FineReader. A rad sa slikama uvelike je pojednostavljen zahvaljujući novom dijalogu. Korištenje aplikacije omogućuje vam prepoznavanje dokumenata napisanih na više jezika, pretvaranje PDF datoteka, prepoznavanje crtičnih kodova i provođenje morfoloških pretraživanja. Iako ovo nije potpuni popis njegovih mogućnosti, samo to može potaknuti mnoge korisnike da trajno instaliraju Fine Reader i koriste ga po potrebi.
I da sumiramo gore navedeno, možemo ukratko navesti ovo: funkcionalnost: Ovaj program se koristi za optičko prepoznavanje različitih tekstualnih dokumenata. Prilikom prepoznavanja teksta program zadržava izvorno oblikovanje i dizajn dokumenta (tekst u boji, tekst na pozadini slika, različiti stilovi fonta, tekst koji se prelama oko slika, tablica itd.). FineReader može raditi sa skeniranim papirnatim dokumentima (radi s gotovo svim popularnim modelima skenera i višenamjenskih uređaja), s dokumentima snimljenim digitalnim fotoaparatima te prepoznaje tekst i grafiku iz PDF datoteka. Također izvozi rezultate optičkog prepoznavanja teksta u popular uredske aplikacije: Word, Excel, PowerPoint, Lotus Word Pro, Corel WordPerfect, OpenOffice. Prepoznati tekst moguće je spremiti u različitim formatima: PDF, PDF/A, DOCX, XLSX, RTF, DOC, XLS, CSV, TXT, HTML, Unicode TXT, Word ML, LIT, DBF.
OCR softver vam omogućuje pretvaranje fotografiranih ili skeniranih dokumenata izravno u rečenice.
Činjenica je da je tekst na slici predstavljen u obliku rastera, skupa točaka. Navedeni softver pretvara skup točaka u potpuni tekst, dostupan za uređivanje i spremanje.
Prepoznavanje slova dizajnirano je za optimizaciju procesa digitalizacije tiskanih ili rukom pisanih knjiga i dokumenata.
Ova metoda digitalizacije je nekoliko redova veličine brža od brzine ručnog tipkanja sa slike. Široko se koristi u digitalizaciji knjižnica i arhiva. Zatim ćemo razmotriti pet najboljih predstavnika obitelji sličnih programa.
ABBYY FineReader 10
FineReader je neupitni lider među svim programima koji prepoznaju tekst na slikama. Konkretno, ne postoji softver koji jasnije obrađuje ćirilicu. Općenito, FineReader ima 179 jezika, tekst na kojima se vrlo uspješno prepoznaje.
Jedina stvar koja može razočarati korisnike je da se program plaća. Distribuira se samo besplatno probna verzija za 15 dana. U tom razdoblju dopušteno je skeniranje 50 stranica.
Zatim ćete morati platiti za korištenje programa. FineReader lako "pojede" više ili manje visokokvalitetna slika. Izvor je potpuno nebitan. Bilo da se radi o fotografiji, skeniranoj stranici ili bilo kojoj slici sa slovima.
Prednosti:
- točno prepoznavanje;
- ogroman broj jezika za čitanje;
- tolerancija na kvalitetu izvorne slike.
Mana:
- probna verzija za 15 dana.
OCR CuneiForm
Besplatni softver za čitanje tekstualne informacije od slika. Točnost prepoznavanja je za red veličine manja nego kod prethodnog programa koji se razmatra. Ali kako za besplatni uslužni program, funkcionalnost je i dalje izvrsna.
Zanimljiv! CuneiForm prepoznaje blokove teksta, grafike, pa čak i razne tablice. Štoviše, mogu se čitati čak i necrtane tablice.
Kako bi se osigurala točnost, posebni rječnici povezani su s procesom prepoznavanja, koji nadopunjuju vokabular iz skeniranih dokumenata.
Prednosti:
- besplatna distribucija;
- korištenje rječnika za provjeru ispravnosti teksta;
- skeniranje teksta s fotokopija loše kvalitete.
Mane:
- relativno niska točnost;
- mali broj podržanih jezika.
WinScan2PDF
Nije ravnomjerno cjelovit program, već uslužni program. Nije potrebna nikakva instalacija, a izvršna datoteka teži samo nekoliko kilobajta. Proces prepoznavanja je iznimno brz, iako se rezultirajući dokumenti spremaju isključivo u PDF formatu.
Naime, cijeli se proces odvija pritiskom na tri tipke: odabirom izvora, odredišta i zapravo pokretanjem programa.
Uslužni program je dizajniran za brzu skupnu obradu mnogih datoteka. Za praktičnost korisnika, osiguran je veliki paket jezika sučelja.
Prednosti:
- prenosivost;
- brz rad;
- Jednostavnost korištenja.
Mane:
- minimalna veličina;
- jedini izlazni format datoteke.
SimpleOCR
Izvrstan mali program za prepoznavanje teksta sa slika. Čak podržava i čitanje rukopisa. Problem je u tome što ruski jezik nije uključen u jezični paket sučelja niti na popisu jezika podržanih za prepoznavanje.
Međutim, ako trebate skenirati engleski, danski ili francuski, nećete pronaći bolju besplatnu opciju.
U svom djelokrugu, program omogućuje precizno dekodiranje fonta, uklanjanje šuma i ekstrakciju grafičke slike. Osim toga, programsko sučelje ima ugrađeno uređivač teksta, gotovo identičan WordPadu, što značajno povećava upotrebljivost programa.
Prednosti:
- točno prepoznavanje teksta;
- zgodan uređivač teksta;
- uklanjanje šuma sa slike.
Mane:
- potpuno odsustvo ruskog jezika.
Freemore OCR
Program vam omogućuje brzo izdvajanje teksta i grafike iz slika. Softver podržava rad s više skenera bez gubitka performansi. Ekstrahirani tekst može se spremiti u tekstualni dokument ili format MS Office dokumenta.
Osim toga, omogućena je funkcija prepoznavanja više stranica.
Freemore OCR se distribuira besplatno, međutim, sučelje je samo na engleskom. Ali ova okolnost ni na koji način ne utječe na jednostavnost korištenja, jer su kontrole organizirane na intuitivan način.
Prednosti:
- besplatna distribucija;
- sposobnost rada s više skenera;
- točnost prepoznavanja je pristojna.
Mane
- Nedostatak ruskog jezika u sučelju;
- Potreba za preuzimanjem ruskog jezičnog paketa za prepoznavanje.
Ako ste odabrali brzi način pisanja teorijskog poglavlja, o kojem smo govorili u paragrafu 2.1., najvjerojatnije nećete moći bez skeniranja dokumenata. U suprotnom, možete preskočiti ovu točku i početi bilježiti materijale pronađene u knjižnici.
Prije nego počnete skenirati, morate odlučiti što točno želite koristiti kada pišete svoj rad. A da biste to učinili, najprije morate pregledati dostupnu literaturu i olovkom istaknuti potrebne točke.
Prvi put kad sam skenirao članak iz časopisa za svoj prvi kolegij, zadatak mi je bio nevjerojatno težak. Kao rezultat višesatnog rada sa skenerom i FineReaderom ispisana je besmislica koja se nije mogla uređivati. Na kraju sam morao sve kucati rukom. Kako vam se to ne bi dogodilo, pogledajmo pobliže sve tehničke aspekte skeniranja.
Za skeniranje će nam, naravno, trebati skener. Ne morate ga kupiti. Možete, primjerice, posuditi nešto od prijatelja na neko vrijeme. Koristim skener CanoScan Lide 60. Iako nije najviše novi model, ali jako mi se sviđa ovaj kompaktni, brz i jednostavan za korištenje “uređaj”. Ako posuđujete skener, da bi radio, prvo morate instalirati upravljački program. Upravljačke programe i upute za instalaciju uvijek možete pronaći na instalacijski disk, koji je uključen u uređaj ili se može preuzeti s web stranice proizvođača. Nakon instaliranja upravljačkog programa, povežite skener s računalom pomoću spojnog kabela. Sada možete izravno započeti skeniranje.
Ali prvo, malo teorije. Trebate znati da se proces skeniranja sastoji od dvije faze:
1. Izravno skeniranje dokumenta. U ovoj fazi skener fotografira površinu dokumenta koji se skenira i sprema dobivenu sliku na računalo kao običnu .jpg .gif datoteku ili u drugom formatu;
2. Prepoznavanje dokumenata. Ovo je proces pretvaranja teksta sa slike snimljene skenerom u uobičajeni test, koji se zatim može spremiti u Word i uređivati. Prepoznavanje se provodi bez sudjelovanja skenera, pomoću posebnog programa (najpopularniji je Adobe FineReader). Na ovaj način možete najprije skenirati nekoliko listova teksta i spremiti ih kao sliku prije pretvaranja u tekst.
Dakle, počnimo prva faza - skeniranje:
– pokrenite upravljački program skenera: Start - Svi programi - Canon - ScanGear(Navodim naziv upravljačkog programa za svoj skener). Pojavit će se prozor upravljačkog programa:
– otvorite poklopac skenera i postavite knjigu, časopis ili primjerak istih s tekstom okrenutim prema dolje, što ravnomjernije u odnosu na rubove radne površine skenera:
Ovdje je vrlo važno osigurati da poklopac skenera pritišće skenirani dokument što je čvršće moguće, sprječavajući vanjsko svjetlo da dopre do radne površine skenera koja je u kontaktu s dokumentom;
- učinimo to potrebne postavke u upravljačkom programu skenera. Prvi korak je postaviti rezoluciju na kojoj će se dokument skenirati. Razlučivost je pokazatelj koji određuje razinu detalja objekta prilikom skeniranja i određuje se u točkama po inču (dpi, ili dpi). Što je veća rezolucija, to je bolja kvaliteta slike. No, kod skeniranja tekstualnih dokumenata nema smisla postavljati maksimalnu rezoluciju jer od toga nema nikakve koristi. Osim toga, skeniranje pri višim rezolucijama traje dulje. Preporučujem postavljanje razlučivosti između 400-500 dpi. Uz ovu postavku slike su dovoljno kvalitetne za dobro prepoznavanje, a sam proces skeniranja ne oduzima puno vremena. Predlažem da pogledate snimak zaslona postavki svog pisača:
 |
Prvo morate ići na “Napredni način rada”. Izvor će uvijek biti "Tableta"(plošni skener). Bolje je postaviti način rada u boji "Crno i bijelo", jer nam ne trebaju boje za skeniranje teksta, a to će smanjiti veličinu izlaznih slika. Rezoluciju, kao što sam rekao, treba odrediti 400 dpi. Veličina izlazne slike – potrebna “A4”. Sada možete sigurno pritisnuti gumb "Skenirati". Moj skener je dizajniran na takav način da prvo pohranjuje skenirane slike Unutarnja memorija, a tek pri zatvaranju prozora upravljačkog programa nudi spremanje na računalo. Sve što trebam učiniti je naznačiti mjesto gdje će biti pohranjeni rezultati rada.
Trebali biste završiti s datotekama ove vrste:

Kada povećate takvu sliku, tekst bi trebao biti jasno vidljiv.
Druga faza – priznanje primljene slike i pretvoriti ih u tekst. Kao što sam već rekao, to će zahtijevati poseban program - FineReader. Preuzmite program s ove poveznice (32MB). Lozinka arhive – web stranica. Verzija koju predlažem ne zahtijeva instalaciju (prijenosna). U mapi programa bit će mnogo različitih datoteka, ali trebate samo jednu - FineReader.exe. Dvostruki klik na ovu datoteku pokrenut će program na vašem računalu.
Ova verzija programa je prilično stara. Uz pomoć njega sam napravio sve snimke zaslona u nastavku. Ako ova verzija FineReader ne radi ti - izaberi noviji.
Prozor FineReader ima sljedeći oblik:

Nakon što postavite jezik na kojem su ispisani dokumenti koje ste prethodno skenirali, možete započeti s prepoznavanjem. Ako tekst sadrži dva jezika odjednom (na primjer, ruski i engleski), izvršite instalaciju u skladu s tim.
Za početak prepoznavanja kliknite na strelicu desno od prvog gumba Skenirati- i onda - Otvori sliku:

Otvorit će se prozor za odabir slike. Otvorite mapu u koju ste spremili skenirane slike, kliknite CTRL+A(engleski) na tipkovnici i pritisnite gumb Otvoren.

Nakon toga lijevo u prozoru FineReader Pojavit će se sličice dodanih datoteka, u sredini - uključeno ovaj trenutak odabrana skica je uvećana, ispod je još veće povećanje, a desno je rezultat prepoznavanja:

Na primjer, snimio sam samo dvije slike. Prvi od njih je istaknut na gornjoj snimci zaslona; sada ga možemo prepoznati. Kao što vidite, slika je skenirana okomito; da bi se prepoznao tekst, slika se prvo mora okrenuti za 90 stupnjeva. Da biste to učinili, koristite gumbe i . Sljedeći korak je reći programu koji dio slike treba prepoznati, kao i postaviti vrstu podataka koji bi trebao biti ispisan: tekst, tablica ili slika. Za to postoje gumbi: . Na primjer, ako trebate označiti blok teksta, kliknite lijevom tipkom miša na , zatim kliknite lijevom tipkom miša u gornjem lijevom kutu bloka teksta i, dok držite lijevi gumb, povucite ga u donji desni kut. Na primjer, u potpunosti sam pripremio jednu sliku za prepoznavanje:

Kao što vidite, svi tekstualni blokovi u gornjem primjeru označeni su zelenom bojom, a slike su označene crvenom bojom. Na isti način se pripremaju tablice za prepoznavanje. Ovome služi gumb. Za prelazak na sljedeću fotografiju kliknite lijevom tipkom miša na njezinu sličicu s lijeve strane. Na taj način se sve slike dobivene skeniranjem pripremaju za prepoznavanje. Nakon što je priprema slika završena, trebate ih sve odabrati. Da biste to učinili, kliknite lijevom tipkom miša na prazan prostor na ploči sa sličicama (naziva se Plastična vrećica) i pritisnite Ctrl+A(engleski) na tipkovnici. Zatim kliknite na gumb i pričekajte dok FineReader pretvara slike u tekst. Nakon toga možete spremiti dobiveni tekst u Word pomoću gumba nakon klika na koji će se otvoriti prozor. U njemu morate odabrati format za spremanje - Microsoft Word, a također potvrdite okvir za spremanje svih stranica:
Nakon pritiska na tipku u redu program će stvoriti Word dokument i u njega umeće tekst s prepoznatih stranica redoslijedom kojim se nalaze na ploči sličica (Batch). Primljeni dokument odmah spremite u mapu u struktura datoteke diplomski rad i možete početi uređivati. Kako se to radi opisano je u mom besplatni tečaj.
I zadnja točka. Ako ste skenirali novine ili časopis, tekst se tamo često daje u obliku stupaca (kao u gornjem primjeru). Ove stupce u Wordu potrebno je pretvoriti u jedan. Odaberite tekst u stupcima i pokrenite naredbu: Format – Stupci – Jedan – OK. Tek nakon toga možete postaviti portretnu orijentaciju u postavkama stranice, ispunu margina, font itd.
Kako skenirati dokument i prepoznati ga u MS Wordu
Pohranjivanje skeniranih dokumenata na tvrdi disk vašeg računala ili vanjski uređaj za pohranu je praktično i sigurno. Međutim, kako napraviti izmjene na stranicama koje su obično predstavljene kao slika? Mi ćemo trebati posebni programičiju ćemo instalaciju i upravljanje opisati u nastavku.
Kako skenirati dokument prije uređivanja?
Da biste u budućnosti uspješno manipulirali datotekom, važno ju je ispravno pretvoriti u format "slike", kao i uzeti u obzir nekoliko jednostavnih, ali korisnih nijansi u samom procesu. Za ovo:
- Izgladite sve nabore i nabore kako se ne bi pojavili na skenu i ne bi doveli do poteškoća u prepoznavanju slova.
- Radi lakšeg snalaženja, spremite datoteku u PDF, JPG ili TIFF formatu.
- PDF dokument se može otvarati i uređivati Adobe program Acrobat (ili bilo koji drugi dizajniran za slične svrhe).
- Idite na web stranicu tvrtke koja je izradila skener ili potražite vlasnički program na priloženom disku (često poznate marke imaju vlastite aplikacije za promjenu skeniranih stranica).
- Za kasniju upotrebu datoteke u MS Office 2003 ili 2007, instalirajte Microsoftov uslužni program Skeniranje uredskih dokumenata. Automatski pretvara skeniranu datoteku, pretvarajući je izravno u tekst (program ne radi s novijim verzijama sustava Office).
- Preporuča se crno-bijelo skeniranje umjesto u boji - to olakšava analizu teksta.
- TIFF format je najbolje koristiti za OCR konvertere, odnosno programe koji vrše optičko prepoznavanje.
Kako urediti skenirani dokument - rad s OCR uslužnim programima
Princip metode optičkog prepoznavanja znakova je čitanje znakova na papiru i njihova usporedba s elementima iz vlastite baze podataka. Na taj se način čvrsta slika pretvara u tekst koji se može uređivati. Živopisni primjeri programa koji se nose s ovim zadatkom su Adobe Acrobat i Evernote. Da biste izvršili ispravke na postojećem skeniranju, jednostavno ga otvorite pomoću jedne od ovih aplikacija, cijeli daljnji proces odvijat će se automatski. Kada program završi s prepoznavanjem, od korisnika će zatražiti spremanje dokumenta u jednom od dostupnih formata.


Kako urediti skenirani PDF dokument
Ako je skenirani dokument spremljen u PDF datoteka, možemo ga jednostavno urediti u programu Acrobat DC. Za ovo:
- otvorite izbornik “Alati” -> “Uredi PDF”;
- program započinje proces uređivanja, prikazujući izbornik s savjetima u gornjem desnom kutu;
- klikom na njega i odabirom opcije "Opcije" možete odrediti jezik prepoznavanja;
- Da biste izvršili izmjene, samo kliknite bilo koji redak dokumenta;
- dokument otvoren za uređivanje putem OCR-a prati posebna ploča s postavkama koja se nalazi na desnoj strani zaslona;
- U odjeljku “Postavke”, osim jezika, zgodno je odabrati i prikazani font te označiti stranice koje je potrebno urediti (sve ili jednu po jednu).


Postoji dostupna alternativa programima pretvarača koji se mogu instalirati na World Wide Webu. Ovo su online OCR-ovi koji mogu jednostavno pretvoriti rezultirajuću sliku u bilo koji tekstualni format. Na primjer, web stranica pdfonline.com omogućuje stvaranje obične MS Word datoteke iz skeniranog PDF dokumenta u nekoliko minuta.
