Jak oříznout naskenovaný dokument ve Wordu. Příklad, jak přenést naskenovaný dokument do Wordu. Rozhraní a dostupné úlohy
Dobré odpoledne všichni!
Myslím si, že ti uživatelé, kteří často vykonávají kancelářskou práci (úpravy a příprava dokumentů, skenování, odesílání atd.), často ztrácejí čas pohráváním si s tím, aby soubory byly reprezentativní.
Například jsem naskenoval tucet nebo dva listy smlouvy a pak se podíváte: některé listy jsou obrácené (nebo obecně, některé jsou navíc)... Co dělat? Můžete znovu naskenovat (což většina udělá), nebo můžete dokument velmi rychle upravit pomocí speciálních nástrojů. programy.
Vlastně se v tomto článku chci podívat na tuto malou část kancelářské práce. Myslím, že to může být užitečné pro mnoho...
Pomoci!
Pokyny pro skenování dokumentů (připojení skeneru k PC, výběr softwaru, získání textu ze skenů atd. dotazy) -
Úprava a úprava dokumentů PDF
1) Co je potřeba pro práci (výběr softwaru)
Předpokládám, že již máte dokument PDF (který chcete upravit). Nyní musíte vybrat software, který chcete změnit. Pro jednoduché a rychlé řešení problému (u kterého jsme se zastavili v tomto článku) udělám Movavi PDF Editor.
Movavi PDF Editor
![]()
Velmi kompaktní a pohodlný program, což vám umožní rychle upravovat soubory PDF! poznamenal bych nízko Požadavky na systém tohoto softwaru k hardwaru, díky čemuž je možné i na „slabých“ kancelářské počítače otevírat a upravovat soubory PDF v vysoká kvalita(v barvě s vysoké rozlišení).
Zvláštnosti:
- k dispozici jsou všechny základní editační funkce: přidávání/mazání stránek, otáčení stránek o 90-180 stupňů, vkládání podpisů, obrázků, slučování/rozdělování dokumentů, PDF převod do obrázků (a zpětná operace);
- program se otevře a umožní vám změnit převážnou většinu PDF (dokonce i docela velkých, s vysokým rozlišením skenování, což je důležité pro kancelář (mnoho jiných programů může jednoduše zamrznout));
- nízké systémové požadavky;
- intuitivní rozhraní (mimochodem, program je zcela v ruštině!);
- kompatibilní s Windows 7, 8, 10 (32/64 bitů).
Snad jediné negativum: plná verze Program stojí 600 rublů. (na testování je však 7 dní).
Níže v článku ukážu hlavní kroky pro práci s editorem Movavi PDF.
2) Otevření dokumentu
O instalaci a spuštění editoru neuvažuji (jsou standardní). Chcete-li otevřít soubor PDF, stačí kliknout na stejnojmenné tlačítko v prvním okně programu. (viz snímek obrazovky níže)
Mimochodem, podotýkám, že program uchovává historii dříve otevřít soubory, která vám časem umožní rychle najít dokumenty, se kterými často pracujete.


Soubor by se měl otevřít v editoru. Rozhraní programu je obecně standardní: všechny stránky dokumentu jsou zobrazeny vlevo a samotný dokument je uprostřed.

Jak vypadá otevřený dokument v Movavi PDF Editor
Nyní můžete přejít k úpravám...
3) Otočte stránky o 90-180°
A tak jsem svůj dokument neotevřel náhodou: některé stránky v něm byly naskenovány vodorovně, ale potřebuji vše ve svislé poloze (Cca. : "pokřivený" specializovaný software skeneru, který byl dodán s ovladači, automaticky naformátuje rozvržení dokumentu při ukládání jako PDF).
Abyste v běžném režimu prohlížení nehledali každou „špatnou“ stránku, doporučuji přejít na přehled všech stránek (klikněte na tlačítko, viz screenshot níže).


Otočení stránek / možnost kliknutí
Operace otáčení stránky se provádějí velmi rychle: doslova dvě nebo tři kliknutí a všechny listy v mých dokumentech se staly vertikálními (viz příklad níže).

Chcete-li se vrátit k normální mód práce s dokumentem klikněte na tlačítko na panelu "Zadní"(viz snímek obrazovky níže).

Upozorňujeme, že stránku můžete také otočit v nabídce vlevo (jediný bod: není příliš pohodlné je zde „hledat“...) .

4) Odebírání a vkládání stránek, obrázků
Pokud jde o odstranit stránku- pak je zde vše jednoduché: nejprve musíte vybrat stránku v nabídce vlevo, poté na ni kliknout pravým tlačítkem a v nabídce vybrat „smazat“ (příklad níže).
Můžete také použít klávesu Delete.

Pokud jde o vkládání nových stránek(a obrázky) do dokumentu, pak je to o něco zajímavější. Nejprve musíte přejít na kartu.

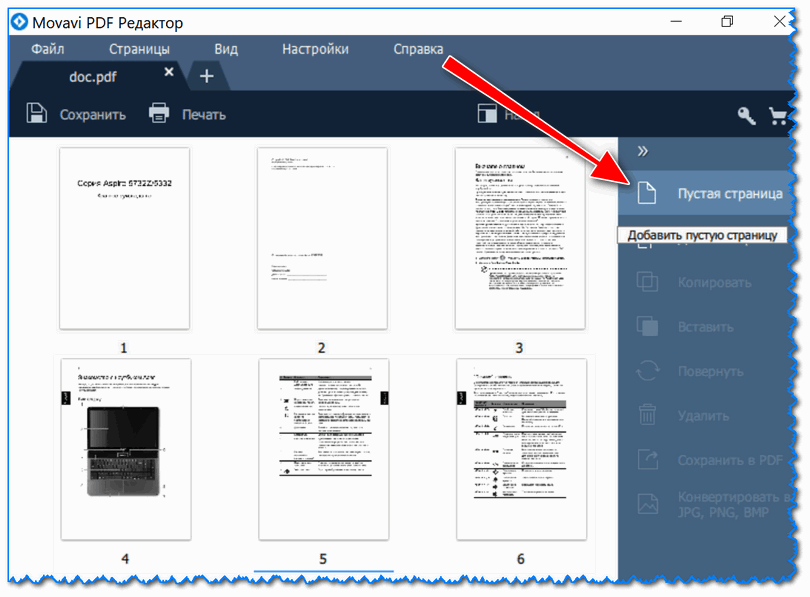
Vezměte prosím na vědomí, že na konci dokumentu budete mít jednu prázdnou stránku. Viz snímek obrazovky níže.

Přetažením této prázdné stránky myší ji můžete přesunout do požadované části dokumentu. Vložil jsem ji například na místo první stránky (mimochodem, stejným způsobem můžete seřadit celý dokument, prohodit stránky a přesunout je na správné místo) .

Chcete-li vložit obrázek (obrázek): jít do požadovanou stránku, V horní menu vyberte možnost. Dále se otevře nabídka Průzkumník, kde si vyberete ten, který potřebujete.

Do upraveného návodu jsem například vložil screenshot, jak zobrazit charakteristiku PC (zejména teplotu HDD). Příklad níže.

Obrázek se přidá do dokumentu
5) Sloučení 2 dokumentů do 1
Také poměrně typický úkol (obzvláště nepříjemný, když jeden dokument obsahuje 3-4 nebo více PDF souborů). Jak je všechny shromáždit do jednoho?
Metoda #1
Nejprve musíte otevřít první dokument (stránku) a přejít do režimu recenze pro všechny stránky (viz snímek obrazovky níže).


Na konci se zobrazí všechny stránky přidaného dokumentu otevřít dokument(omlouvám se za tautologii). Tím vlastně „slepíme“ dva dokumenty do jednoho.

Průběžné přidávání všech „malých“ dokumentů – budete si z nich moci sestavit jeden „velký“, který jste původně chtěli...
Metoda #2
Tato možnost je jednodušší. Po spuštění programu stačí kliknout na tlačítko (na spouštěcím okně vpravo).

Mimochodem!
Pokud se váš dokument PDF ukáže být příliš velký (a to se také čas od času stává), můžete jej zkomprimovat. V jednom ze svých předchozích článků jsem uvedl několik možností, doporučuji -
To je prozatím vše. Doplňky jsou vítány...
Program pro optické rozpoznávání textu. ABBYY FineReader dokáže rozpoznat text z naskenovaných papírových dokumentů, souborů PDF a dokumentů pořízených digitálním fotoaparátem. Textové dokumenty rozpoznané programem lze dále upravovat pomocí aplikace společnosti Microsoft Kancelář. V případě potřeby bude při rozpoznávání textu zachována celá struktura návrhu dokumentu. FineReader funguje se všemi oblíbenými modely moderních skenerů a multifunkční zařízení(MFP). Pokud uživatel potřebuje naskenovat a rozpoznat velké množství stránek textu, pak program poskytuje speciální režim pro práci automatické skenery(skener s automatickým podavačem papíru). Program dokáže rozpoznat text v souborech následujících formátů: PDF, BMP, PCX, DCX, JPEG, JPEG 2000, TIFF, PNG, DjVu; v případě potřeby budou zpracovány digitální obrázky pro zlepšení kvality optického rozpoznávání textu (obrázek lze oříznout a zbavit nepotřebných prvků, odstranit nepřesnosti, zkreslení čar, otočit nebo zrcadlit).Program je komplexní aplikací pro práci s textovými dokumenty. Jeho hlavním účelem je optické rozpoznávání znaků. Tvůrcem programu je ruská společnost ABBYY Software (světová jednička v oblasti rozpoznávacích systémů). Aplikace rychle a přesně převede naskenované dokumenty do upravitelného formátu, přičemž zachová všechny podrobnosti o původním zdroji. FineReader dokáže rozpoznat soubory PDF, digitální fotografie a papírové dokumenty. Program přesně reprodukuje vzhled původního zdroje, podporuje rozpoznávání textu ve 186 jazycích a poskytuje přímý export do aplikací Microsoft Office.
Pomocí aplikace lze provádět úkoly jako: vytváření a úprava elektronických dokumentů na základě papírových zdrojů, překlad dokumentů nízké kvality do editovatelného formátu, zpracování dokumentů se složitou obsahovou strukturou včetně tabulek, ilustrací, diagramů atd., vyhledávání a úprava textu jsou řešeny v libovolných formátech. Podle většiny odborníků je program nejlepší ve svém oboru.
Pokud mluvíme o praxi používání tohoto programu na RuNet, pak mnoho uživatelů již dlouho zná tento program Fine Reader (ruský překlad názvu), jehož hlavním účelem je provádět takzvané optické rozpoznávání textu. Zjednodušeně lze pomocí tohoto programu převést jakýkoli text vytištěný na papír do některého z elektronických formátů. Nejnovější verze program je nejen aktualizován a další uživatelsky přívětivé rozhraní, ale také vylepšenou funkčnost.
Ve skutečnosti lze všechny základní akce provést jedním kliknutím myši, které vybere jednu z akcí nabízených při spuštění programu. Mezi ně patří možnost skenovat dokumenty do formátu .doc, převádět fotografie, skenovat do Excelu, ukládat obrázky a skenovat je, rozpoznávání obrázků atd. Aby se zlepšila použitelnost programu, Pracovní prostor byla zvětšena a tlačítka, která spouštějí tu či onu akci, jsou nyní na postranním panelu.
Aby nebyl uživatel zmaten, jsou ve výchozím nastavení automaticky rozpoznány všechny soubory, které otevře. V případě potřeby může zkušený uživatel provést hluboké úpravy funkčnosti FineReaderu. A práce s obrázky se díky novému dialogu výrazně zjednodušila. Používání aplikace umožňuje rozpoznávat dokumenty napsané ve více než jednom jazyce, převádět soubory PDF, rozpoznávat čárové kódy a provádět morfologické vyhledávání. A ačkoli to zdaleka není úplný seznam jeho schopností, toto samo o sobě může povzbudit mnoho uživatelů, aby si Fine Reader nainstalovali trvale a používali jej podle potřeby.
A abychom shrnuli výše uvedené, můžeme stručně nastínit toto: funkčnost: Tento program se používá pro optické rozpoznávání různých textových dokumentů. Při rozpoznávání textu program zachovává původní formátování a design dokumentu (barevný text, text na pozadí obrázků, různé styly písma, obtékání textu kolem obrázků, tabulek atd.). FineReader umí pracovat s naskenovanými papírovými dokumenty (funguje téměř se všemi oblíbenými modely skenerů a multifunkčních zařízení), s dokumenty zachycenými digitálními fotoaparáty a rozpoznává text a grafiku ze souborů PDF. Exportuje také výsledky optického rozpoznávání textu do oblíbených kancelářské aplikace: Word, Excel, PowerPoint, Lotus Word Pro, Corel WordPerfect, OpenOffice. Rozpoznaný text lze uložit v různých formátech: PDF, PDF/A, DOCX, XLSX, RTF, DOC, XLS, CSV, TXT, HTML, Unicode TXT, Word ML, LIT, DBF.
Software OCR umožňuje převádět vyfotografované nebo naskenované dokumenty přímo na věty.
Faktem je, že text na obrázku je prezentován ve formě rastru, sady bodů. Zmíněný software převede sadu teček na plnohodnotný text, dostupný pro editaci a uložení.
Rozpoznávání písmen je navrženo tak, aby optimalizovalo proces digitalizace tištěných nebo ručně psaných knih a dokumentů.
Tato metoda digitalizace je řádově rychlejší než rychlost ručního psaní z obrázku. Široce se používá při digitalizaci knihoven a archivů. Dále zvážíme pět nejlepších zástupců rodiny podobných programů.
ABBYY FineReader 10
FineReader je nesporným lídrem mezi všemi programy, které rozpoznávají text v obrázcích. Konkrétně neexistuje žádný software, který by azbuku zpracoval přehledněji. FineReader má obecně 179 jazyků, jejichž text je rozpoznán mimořádně úspěšně.
Jediné, co může uživatele zklamat, je, že program je placený. Distribuováno pouze zdarma zkušební verze po dobu 15 dnů. Během této doby je povoleno skenování 50 stran.
Za používání programu pak budete muset zaplatit. FineReader snadno „sežere“ více či méně vysoce kvalitní obraz. Zdroj je naprosto nepodstatný. Ať už je to fotografie, sken stránky nebo jakýkoli obrázek s písmeny.
výhody:
- přesné rozpoznávání;
- obrovské množství jazyků čtení;
- tolerance ke kvalitě zdrojového obrazu.
Chyba:
- zkušební verze na 15 dní.
OCR CuneiForm
Software pro čtení zdarma textové informace z obrázků. Přesnost rozpoznávání je o řád nižší než u předchozího uvažovaného programu. Ale jak pro bezplatný nástroj, funkčnost je stále vynikající.
Zajímavý! CuneiForm rozpoznává bloky textu, grafiky a dokonce i různé tabulky. Navíc lze číst i nelinkované tabulky.
Pro zajištění přesnosti jsou na proces rozpoznávání napojeny speciální slovníky, které doplňují slovní zásobu z naskenovaných dokumentů.
výhody:
- bezplatná distribuce;
- používání slovníků ke kontrole správnosti textu;
- skenování textu z nekvalitních fotokopií.
nedostatky:
- relativně nízká přesnost;
- malý počet podporovaných jazyků.
WinScan2PDF
Není to ani plnohodnotný program, ale utilita. Není nutná žádná instalace a spustitelný soubor váží pouze několik kilobajtů. Proces rozpoznávání je extrémně rychlý, přestože výsledné dokumenty jsou uloženy výhradně ve formátu PDF.
Ve skutečnosti se celý proces provádí stisknutím tří tlačítek: výběrem zdroje, cíle a vlastně spuštěním programu.
Nástroj je navržen pro rychlé dávkové zpracování mnoha souborů. Pro pohodlí uživatelů je k dispozici velký jazykový balíček rozhraní.
výhody:
- přenosnost;
- rychlá práce;
- snadnost použití.
nedostatky:
- minimální velikost;
- jediný výstupní formát souboru.
Jednoduché OCR
Výborný malý program na rozpoznávání textů z obrázků. Podporuje dokonce i čtení rukopisů. Problém je v tom, že ruština není zahrnuta ani v jazykovém balíčku rozhraní, ani v seznamu jazyků podporovaných pro rozpoznávání.
Pokud však potřebujete skenovat angličtinu, dánštinu nebo francouzštinu, pak nenajdete lepší bezplatnou možnost.
Program ve svém rozsahu poskytuje přesné dekódování písem, odstranění šumu a extrakci grafického obrazu. Kromě toho má vestavěné rozhraní programu textový editor, téměř identický s WordPadem, což výrazně zvyšuje použitelnost programu.
výhody:
- přesné rozpoznávání textu;
- pohodlný textový editor;
- odstranění šumu z obrazu.
nedostatky:
- úplná absence ruského jazyka.
Freemore OCR
Program umožňuje rychle extrahovat text a grafiku z obrázků. Software podporuje práci s více skenery bez ztráty výkonu. Extrahovaný text lze uložit ve formátu textového dokumentu nebo dokumentu MS Office.
Kromě toho je k dispozici funkce rozpoznávání více stránek.
Freemore OCR je distribuován zdarma, nicméně rozhraní je pouze v angličtině. Tato okolnost ale nijak neovlivňuje snadnost použití, protože ovládání je organizováno intuitivním způsobem.
výhody:
- bezplatná distribuce;
- schopnost pracovat s více skenery;
- přesnost rozpoznávání je slušná.
Nedostatky
- Nedostatek ruského jazyka v rozhraní;
- Nutnost stáhnout ruský jazykový balíček pro rozpoznání.
Pokud jste zvolili rychlý způsob psaní teoretické kapitoly, o kterém jsme hovořili v odstavci 2.1., s největší pravděpodobností se bez skenování dokumentů neobejdete. V opačném případě můžete tento bod přeskočit a začít si dělat poznámky k materiálům nalezeným v knihovně.
Než začnete skenovat, musíte se rozhodnout, co přesně chcete při psaní práce použít. A k tomu je potřeba nejprve prolistovat dostupnou literaturu a zvýraznit si potřebné body tužkou.
Když jsem poprvé naskenoval článek v časopise pro svou první práci v kurzu, shledal jsem tento úkol neuvěřitelně obtížným. V důsledku několikahodinové práce se skenerem a FineReaderem byl výstup nesmysl, který nebylo možné upravovat. Nakonec jsem musel vše psát ručně. Aby se vám to nestalo, podívejme se blíže na všechny technické aspekty skenování.
Ke skenování budeme samozřejmě potřebovat skener. Nemusíte to kupovat. Můžete si třeba na chvíli něco půjčit od kamaráda. Používám skener CanoScan Lide 60. I když to není nejvíc nový model, ale moc se mi líbí toto kompaktní, rychlé a snadno použitelné „zařízení“. Pokud si půjčíte skener, aby fungoval, musíte nejprve nainstalovat program ovladače. Ovladače a pokyny k instalaci naleznete vždy na instalační disk, který je součástí zařízení nebo si jej lze stáhnout z webu výrobce. Po instalaci ovladače připojte skener k počítači pomocí propojovacího kabelu. Nyní můžete začít skenovat přímo.
Nejprve ale trocha teorie. Měli byste vědět, že proces skenování se skládá ze dvou fází:
1. Přímé skenování dokumentu. V této fázi skener vyfotografuje povrch skenovaného dokumentu a výsledný obrázek uloží do počítače jako běžný soubor .jpg .gif nebo v jiném formátu;
2. Rozpoznávání dokumentů. Jedná se o proces převodu textu z obrázku pořízeného skenerem na běžný test, který lze následně uložit ve Wordu a upravit. Rozpoznávání se provádí bez účasti skeneru pomocí speciálního programu (nejoblíbenější je Adobe FineReader). Tímto způsobem můžete nejprve naskenovat několik listů textu a uložit je jako obrázek, než je převedete na text.
Takže, začněme první fáze - skenování:
– spusťte ovladač skeneru: Start - Všechny programy - Canon - ScanGear(Uvádím název ovladače pro můj skener). Zobrazí se okno ovladače:
– otevřete víko skeneru a položte knihu, časopis nebo jejich kopii textem dolů, pokud možno rovnoměrně vzhledem k okrajům pracovní plochy skeneru:
Zde je velmi důležité zajistit, aby víko skeneru přitlačilo naskenovaný dokument co nejtěsněji a zabránilo vnějším světlu proniknout na pracovní plochu skeneru, která je v kontaktu s dokumentem;
- Pojďme na to potřebná nastavení v ovladači skeneru. Prvním krokem je nastavení rozlišení, ve kterém bude dokument skenován. Rozlišení je indikátor, který určuje úroveň detailů objektu při skenování a je určen v bodech na palec (dpi nebo dpi). Čím vyšší rozlišení, tím lepší kvalita obrazu. Při skenování textových dokumentů však nemá smysl nastavovat maximální rozlišení, protože to nebude užitečné. Skenování ve vyšším rozlišení navíc trvá déle. Doporučuji nastavit rozlišení mezi 400-500 dpi. S tímto nastavením jsou obrázky dostatečně kvalitní pro dobré rozpoznání a samotný proces skenování nezabere mnoho času. Doporučuji podívat se na snímek obrazovky nastavení mé tiskárny:
 |
Nejprve musíte jít do "Pokročilý mód". Zdroj bude vždy "Tableta"(plochý skener). Je lepší nastavit barevný režim "Černý a bílý", protože ke skenování textu nepotřebujeme barvy, což zmenší velikost výstupních obrázků. Jak jsem řekl, mělo by být stanoveno usnesení 400 dpi. Velikost výstupního obrázku – povinná "A4". Nyní můžete bezpečně stisknout tlačítko "Skenovat". Můj skener je navržen tak, že nejprve uloží naskenované obrázky vnitřní paměť a pouze při zavření okna ovladače nabídne jejich uložení do počítače. Stačí mi uvést místo, kam se výsledky práce uloží.
Měli byste skončit se soubory tohoto typu:

Když takový obrázek zvětšíte, text by měl být dobře viditelný.
Druhá fáze – uznání přijaté obrázky a převést je na text. Jak jsem již řekl, bude to vyžadovat speciální program - FineReader. Stáhněte si program z tohoto odkazu (32 MB). Heslo archivu – webové stránky. Verze, kterou navrhuji, nevyžaduje instalaci (přenosná). Ve složce programu bude mnoho různých souborů, ale potřebujete pouze jeden - FineReader.exe. Dvojitým kliknutím na tento soubor spustíte program na vašem počítači.
Tato verze programu je poměrně stará. Pořídil jsem pomocí něj všechny níže uvedené snímky obrazovky. Pokud tato verze FineReader nefunguje ti to - vyber si novější.
Okno FineReader má následující podobu:

Po nastavení jazyka, ve kterém byly vytištěny dříve naskenované dokumenty, můžete zahájit rozpoznávání. Pokud text obsahuje dva jazyky najednou (například ruština a angličtina), proveďte instalaci odpovídajícím způsobem.
Pro zahájení rozpoznávání klikněte na šipku vpravo od prvního tlačítka Skenovat- a pak - Otevřít obrázek:

Otevře se okno pro výběr obrázku. Otevřete složku, do které jste uložili naskenované obrázky, klepněte na CTRL+A(anglicky) na klávesnici a stiskněte tlačítko OTEVŘENO.

Poté vlevo v okně FineReader Uprostřed se zobrazí miniatury přidaných souborů - na tento moment vybraný náčrt se zvětší, dole je ještě větší nárůst a vpravo je výsledek rozpoznání:

Například jsem pořídil pouze dva snímky. První z nich je zvýrazněn na snímku obrazovky výše; nyní jej poznáme. Jak vidíte, obrázek byl naskenován vertikálně, aby bylo možné text rozpoznat, je nutné obrázek nejprve otočit o 90 stupňů. K tomu použijte tlačítka a . Dalším krokem je sdělit programu, která část obrázku má být rozpoznána, a také nastavit typ dat, která mají být na výstupu: text, tabulka nebo obrázek. K tomu slouží tlačítka, respektive: . Pokud například potřebujete označit textový blok, klikněte levým tlačítkem na , poté klikněte levým tlačítkem do levého horního rohu textového bloku a podržte levé tlačítko, přetáhněte jej do pravého dolního rohu. Plně jsem například připravil jeden obrázek k rozpoznání:

Jak vidíte, všechny textové bloky ve výše uvedeném příkladu jsou zvýrazněny zeleně a obrázky jsou zvýrazněny červeně. Tabulky jsou připraveny k rozpoznání stejným způsobem. K tomu slouží tlačítko. Chcete-li přejít na další fotografii, klikněte levým tlačítkem na její miniaturu vlevo. Tímto způsobem jsou všechny obrázky získané skenováním připraveny k rozpoznání. Po dokončení přípravy snímků byste je měli všechny vybrat. Chcete-li to provést, klikněte levým tlačítkem myši na prázdné místo na panelu miniatur (tzv Igelitová taška) a stiskněte Ctrl+A(anglicky) na klávesnici. Dále klikněte na tlačítko a počkejte, dokud FineReader převádí obrázky na text. Poté můžete výsledný text uložit ve Wordu pomocí tlačítka, po kliknutí na které se otevře okno. V něm musíte vybrat formát pro uložení - Microsoft Word a také zaškrtnutím políčka uložíte všechny stránky:
Po stisknutí tlačítka OK program vytvoří Word dokument a vloží do něj text z rozpoznaných stránek v pořadí, v jakém jsou umístěny na panelu miniatur (Dávka). Přijatý dokument okamžitě uložte do složky v struktura souboru práce a můžete začít upravovat. Jak se to dělá, je popsáno v mém volný kurz.
A poslední bod. Pokud jste naskenovali noviny nebo časopis, text je často uveden ve formě sloupců (jako v příkladu výše). Tyto sloupce ve Wordu je třeba převést na jeden. Vyberte text ve sloupcích a spusťte příkaz: Formát – Sloupce – Jeden – OK. Teprve poté můžete nastavit orientaci na výšku v Nastavení stránky, odsazení okrajů, písmo atd.
Jak naskenovat dokument a rozpoznat jej v MS Word
Ukládání naskenovaných dokumentů na pevný disk počítače nebo externí úložné zařízení je pohodlné a bezpečné. Jak však provedete změny na stránkách, které jsou obvykle prezentovány jako obrázek? Budeme potřebovat speciální programy, jehož instalaci a správu popíšeme níže.
Jak naskenovat dokument před úpravou?
Aby bylo možné úspěšně manipulovat se souborem v budoucnu, je důležité jej správně převést do „obrázkového“ formátu a také vzít v úvahu několik jednoduchých, ale užitečných nuancí v samotném procesu. Pro tohle:
- Vyhlaďte všechny záhyby a záhyby, aby se na skenu neobjevily a nevedly k potížím s rozpoznáváním písmen.
- Pro snazší orientaci uložte soubor ve formátu PDF, JPG nebo TIFF.
- Dokument PDF lze otevřít a upravit program Adobe Acrobat (nebo jakýkoli jiný určený pro podobné účely).
- Přejděte na web společnosti, která skener vytvořila, nebo vyhledejte proprietární program na přiloženém disku (známé značky mají často vlastní aplikace pro změnu naskenovaných stránek).
- Pro následné použití souboru v MS Office 2003 nebo 2007 nainstalujte Nástroj společnosti Microsoft Skenování kancelářských dokumentů. Automaticky převede naskenovaný soubor a převede jej přímo na text (program nefunguje s novějšími verzemi Office).
- Doporučuje se skenovat spíše černobíle než barevně – to usnadňuje analýzu textu.
- Formát TIFF se nejlépe používá pro převodníky OCR, tedy programy provádějící optické rozpoznávání.
Jak upravit naskenovaný dokument - práce s nástroji OCR
Principem metody optického rozpoznávání znaků je čtení znaků na papíře a následné porovnání s prvky z vlastní databáze. Tímto způsobem se pevný obrázek převede na upravitelný text. Živými příklady programů, které se s tímto úkolem vypořádají, jsou Adobe Acrobat a Evernote. Chcete-li provést opravy stávajícího skenování, jednoduše jej otevřete pomocí jedné z těchto aplikací, celý následující proces proběhne automaticky. Když program dokončí rozpoznávání, vyzve uživatele k uložení dokumentu v jednom z dostupných formátů.


Jak upravit naskenovaný dokument PDF
Pokud je naskenovaný dokument uložen v PDF soubor, můžeme jej snadno upravit v aplikaci Acrobat DC. Pro tohle:
- otevřete nabídku „Nástroje“ -> „Upravit PDF“;
- program zahájí proces úprav a zobrazí nabídku nápovědy v pravém horním rohu;
- kliknutím na něj a výběrem „Možnosti“ můžete určit jazyk rozpoznávání;
- Chcete-li provést změny, stačí kliknout na libovolný řádek dokumentu;
- dokument otevřený pro úpravy pomocí OCR je doprovázen speciálním panelem s nastavením umístěným na pravé straně obrazovky;
- V sekci „Nastavení“ je kromě jazyka vhodné také vybrat zobrazené písmo a označit stránky, které je potřeba upravit (všechny nebo po jedné).


Na World Wide Web existuje dostupná alternativa k instalovatelným převaděčům. Jedná se o online OCR, které dokážou výsledný obrázek snadno převést do libovolného textového formátu. Například web pdfonline.com vám umožní vytvořit běžný soubor MS Word z naskenovaného PDF dokumentu během několika minut.
