Hvordan beskjære et skannet dokument i Word. Et eksempel på hvordan du overfører et skannet dokument til Word. Grensesnitt og tilgjengelige oppgaver
God ettermiddag alle sammen!
Jeg tror at de brukerne som ofte gjør kontorarbeid (redigering og klargjøring av dokumenter, skanning, sending osv.) ofte kaster bort tid på å fikle med å gjøre filer presentable.
For eksempel skannet jeg et dusin eller to ark av kontrakten, og så ser du: noen av arkene er opp ned (eller generelt sett er noen ark ekstra)... Hva skal jeg gjøre? Du kan skanne på nytt (som er det de fleste vil gjøre), eller du kan veldig raskt redigere dokumentet ved hjelp av spesialverktøy. programmer.
Egentlig vil jeg i denne artikkelen se på denne lille delen av kontorarbeid. Jeg tror det kan være nyttig for mange...
Å hjelpe!
Instruksjoner for å skanne dokumenter (koble skanneren til en PC, velge programvare, hente tekst fra skanninger osv. spørsmål) -
Endre og redigere PDF-dokumenter
1) Hva trengs for arbeid (programvarevalg)
Jeg vil anta at du allerede har PDF-dokumentet (som du vil redigere). Nå må du velge programvare for å endre den. For en enkel og rask løsning på problemet (som vi stoppet ved i denne artikkelen) Vil gjøre Movavi PDF Editor.
Movavi PDF Editor
![]()
Veldig kompakt og praktisk program, slik at du raskt kan redigere PDF-filer! Jeg vil notere lavt Systemkrav av denne programvaren til maskinvaren, takket være hvilken det er mulig selv på "svak" kontordatamaskineråpne og redigere PDF-filer i høy kvalitet(i farger med høy oppløsning).
Egenskaper:
- det er alle grunnleggende redigeringsfunksjoner: legge til/slette sider, rotere sider 90-180 grader, sette inn signaturer, bilder, slå sammen/dele dokumenter, PDF-konvertering til bilder (og omvendt operasjon);
- programmet åpnes og lar deg endre de aller fleste PDF-filer (selv ganske store, med høy skanneoppløsning, noe som er viktig for kontoret (mange andre programmer kan ganske enkelt fryse));
- lave systemkrav;
- intuitivt grensesnitt (forresten, programmet er helt på russisk!);
- kompatibel med Windows 7, 8, 10 (32/64 bits).
Kanskje det eneste negative: fullversjon Programmet koster 600 rubler. (det er imidlertid 7 dager til testing).
Nedenfor i artikkelen vil jeg vise hovedtrinnene for å jobbe med Movavi PDF-editor.
2) Åpne et dokument
Jeg vurderer ikke å installere og starte editoren (de er standard). For å åpne en PDF-fil, klikker du bare på knappen med samme navn i det første vinduet i programmet. (se skjermbilde nedenfor)
Jeg noterer meg forresten at programmet fører historikk tidligere åpne filer, som over tid lar deg raskt finne dokumenter som du ofte jobber med.


Filen skal åpnes i editoren. Programgrensesnittet er generelt standard: alle sidene i dokumentet presenteres til venstre, og selve dokumentet er i midten.

Hvordan et åpent dokument ser ut i Movavi PDF Editor
Nå kan du gå videre til redigering...
3) Roter sidene 90-180°
Og så, det var ikke tilfeldig at jeg åpnet dokumentet mitt: noen sider i det ble skannet horisontalt, men jeg trenger alt i vertikal posisjon (ca. : "skjev" spesialisert skannerprogramvare som fulgte med driverne formaterer automatisk dokumentoppsettet ved lagring som PDF).
For ikke å se etter hver "feil" side i normal visningsmodus, anbefaler jeg å gå til oversikten over alle sider (for å gjøre dette, klikk på knappen, se skjermbildet nedenfor).


Roter sider / klikkbar
Siderotasjonsoperasjoner utføres veldig raskt: bokstavelig talt to eller tre klikk og alle arkene i dokumentene mine ble vertikale (se eksempel nedenfor).

Å gå tilbake til normal modus arbeid med dokumentet, klikk på knappen på panelet "Tilbake"(se skjermbilde nedenfor).

Vær oppmerksom på at du også kan rotere siden i menyen til venstre (det eneste poenget: det er ikke veldig praktisk å "se etter" dem her ...) .

4) Fjerning og innsetting av sider, bilder
Angående slette siden- da er alt enkelt her: først må du velge siden i menyen til venstre, deretter høyreklikke på den og velge "slett" i menyen (eksempel nedenfor).
Du kan også bruke Delete-tasten.

Når det gjelder legge inn nye sider(og bilder) inn i dokumentet, så er dette litt mer interessant. Først må du gå til fanen.

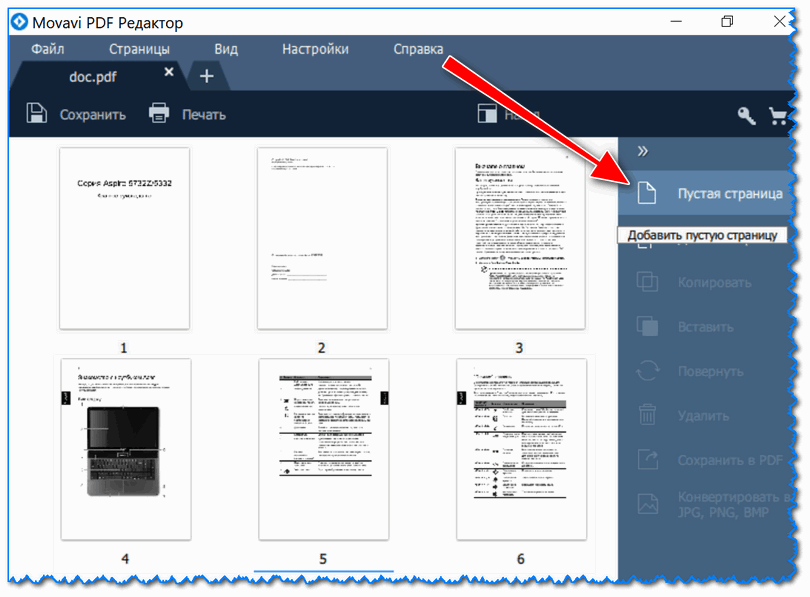
Vær oppmerksom på at du vil ha én tom side på slutten av dokumentet. Se skjermbilde nedenfor.

Ved å dra denne tomme siden med musen, kan du flytte den til ønsket del av dokumentet. For eksempel satte jeg den inn i stedet for den første siden (Du kan forresten sortere hele dokumentet på samme måte, bytte sider og flytte dem til riktig sted) .

For å sette inn et bilde (bilde): gå til ønsket side, V toppmenyen velg alternativ. Deretter åpnes Utforsker-menyen, hvor du kan velge den du trenger.

For eksempel la jeg inn et skjermbilde i de redigerte instruksjonene om hvordan du kan se egenskapene til en PC (spesielt HDD-temperatur). Eksempel nedenfor.

Bildet legges til dokumentet
5) Kombinere 2 dokumenter til 1
Også en ganske typisk oppgave (spesielt ubehagelig når ett dokument består av 3-4 eller flere PDF-filer). Hvordan samle dem alle i ett?
Metode #1
Først må du åpne det første dokumentet (siden) og gå til gjennomgangsmodus for alle sider (se skjermbilde nedenfor).


Alle sidene i det lagte dokumentet vises på slutten åpne dokumentet(beklager tautologien). Dermed "limer" vi faktisk to dokumenter til ett.

Konsekvent legge til alle de "små" dokumentene - du vil kunne sette sammen ett "stort" som du ønsket i utgangspunktet...
Metode #2
Dette alternativet er enklere. Etter å ha startet programmet, klikker du bare på knappen (i startvinduet til høyre).

Forresten!
Hvis PDF-dokumentet ditt viser seg å være for stort (og dette skjer også fra tid til annen), kan du komprimere det. I en av mine tidligere artikler ga jeg flere alternativer, anbefaler jeg -
Det er alt for nå. Tillegg er velkomne...
Optisk tekstgjenkjenningsprogram. ABBYY FineReader kan gjenkjenne tekst fra skannede papirdokumenter, PDF-filer og dokumenter tatt med et digitalkamera. Tekstdokumenter som gjenkjennes av programmet kan redigeres ytterligere ved hjelp av Microsoft-applikasjoner Kontor. Om nødvendig vil hele strukturen til dokumentdesign bli bevart under tekstgjenkjenning. FineReader fungerer med alle populære modeller av moderne skannere og multifunksjonelle enheter(MFP). Hvis brukeren trenger å skanne og gjenkjenne et stort antall sider med tekst, gir programmet en spesiell modus for å arbeide med automatiske skannere(skanner med automatisk papirmater). Programmet kan gjenkjenne tekst i filer med følgende formater: PDF, BMP, PCX, DCX, JPEG, JPEG 2000, TIFF, PNG, DjVu; om nødvendig vil digitale bilder bli behandlet for å forbedre kvaliteten på optisk tekstgjenkjenning (bildet kan beskjæres og fjernes for unødvendige elementer, eliminere unøyaktigheter, forvrengning av linjer, rotere eller speil).Programmet er et omfattende program for arbeid med tekstdokumenter. Hovedformålet er optisk tegngjenkjenning. Skaperen av programmet er det russiske selskapet ABBYY Software (verdensleder innen gjenkjenningssystemer). Applikasjonen oversetter raskt og nøyaktig skannede dokumenter til et redigerbart format, og bevarer alle originale kildedetaljer. FineReader kan gjenkjenne PDF-filer, digitale bilder og papirdokumenter. Programmet gjengir nøyaktig utseendet til den opprinnelige kilden, støtter tekstgjenkjenning på 186 språk og gir direkte eksport til Microsoft Office-applikasjoner.
Bruk av applikasjonen oppgaver som: opprette og redigere elektroniske dokumenter basert på papirkilder, oversette dokumenter av dårlig kvalitet til et redigerbart format, behandle dokumenter med en kompleks innholdsstruktur, inkludert tabeller, illustrasjoner, diagrammer osv., søke og redigere tekst løses i alle formater. Ifølge de fleste eksperter er programmet det beste innen sitt felt.
Hvis vi snakker om praksisen med å bruke dette programmet på RuNet, har mange brukere lenge kjent dette programmet Fine Reader (russisk oversettelse av navnet), hvis hovedformål er å utføre såkalt optisk tekstgjenkjenning. For å si det enkelt, ved hjelp av dette programmet kan all tekst som er trykt på papir konverteres til et av de elektroniske formatene. Siste versjon programmet er ikke bare oppdatert og mer brukervennlig grensesnitt, men også forbedret funksjonalitet.
Faktisk kan alle grunnleggende handlinger utføres med ett museklikk, som velger en av handlingene som tilbys når du starter programmet. Blant dem er muligheten til å skanne dokumenter til .doc-format, konvertere bilder, skanne til Excel, lagre bilder og skanne dem, bildegjenkjenning osv. For å forbedre brukervennligheten til programmet, Arbeidsområde har blitt forstørret, og knappene som utløser denne eller den handlingen er nå på sidefeltet.
For ikke å forvirre brukeren, gjenkjennes som standard alle filer han åpner automatisk. Om nødvendig kan en erfaren bruker gjøre dype justeringer av FineReader-funksjonaliteten. Og arbeidet med bilder har blitt betraktelig forenklet takket være den nye dialogen. Ved å bruke applikasjonen kan du gjenkjenne dokumenter skrevet på mer enn ett språk, konvertere PDF-filer, gjenkjenne strekkoder og utføre morfologiske søk. Og selv om dette er langt fra en fullstendig liste over funksjonene, kan dette alene oppmuntre mange brukere til å installere Fine Reader på permanent basis og bruke den etter behov.
Og for å oppsummere det ovenstående, kan vi kort skissere dette: funksjonalitet: Dette programmet brukes til optisk gjenkjenning av ulike tekstdokumenter. Når du gjenkjenner tekst, bevarer programmet den originale formateringen og utformingen av dokumentet (farget tekst, tekst mot bakgrunnen til bilder, forskjellige skriftstiler, tekstomvikling rundt bilder, tabeller osv.). FineReader kan arbeide med skannede papirdokumenter (fungerer med nesten alle populære modeller av skannere og multifunksjonsenheter), med dokumenter tatt opp av digitale kameraer, og gjenkjenner tekst og grafikk fra PDF-filer. Den eksporterer også resultater for optisk tekstgjenkjenning til populære kontorapplikasjoner: Word, Excel, PowerPoint, Lotus Word Pro, Corel WordPerfect, OpenOffice. Gjenkjent tekst kan lagres i ulike formater: PDF, PDF/A, DOCX, XLSX, RTF, DOC, XLS, CSV, TXT, HTML, Unicode TXT, Word ML, LIT, DBF.
OCR-programvare lar deg konvertere fotograferte eller skannede dokumenter direkte til setninger.
Faktum er at teksten i bildet presenteres i form av et raster, et sett med prikker. Den nevnte programvaren konverterer et sett med prikker til fullverdig tekst, tilgjengelig for redigering og lagring.
Bokstavgjenkjenning er designet for å optimalisere prosessen med å digitalisere trykte eller håndskrevne bøker og dokumenter.
Denne digitaliseringsmetoden er størrelsesordener raskere enn hastigheten på manuell skriving fra et bilde. Mye brukt i digitalisering av biblioteker og arkiver. Deretter vil vi vurdere de fem beste representantene for familien til lignende programmer.
ABBYY FineReader 10
FineReader er den ubestridte lederen blant alle programmer som gjenkjenner tekst i bilder. Spesielt er det ingen programvare som behandler det kyrilliske alfabetet klarere. Generelt har FineReader 179 språk, teksten som gjenkjennes ekstremt vellykket.
Det eneste som kan skuffe brukere er at programmet er betalt. Deles kun ut gratis prøveversjon i 15 dager. I denne perioden er skanning av 50 sider tillatt.
Du må da betale for å bruke programmet. FineReader "spiser" enkelt mer eller mindre bilde av høy kvalitet. Kilden er helt uviktig. Det være seg et fotografi, en skanning av en side eller et hvilket som helst bilde med bokstaver.
Fordeler:
- nøyaktig gjenkjennelse;
- et stort antall lesespråk;
- toleranse for kvaliteten på kildebildet.
Feil:
- prøveversjon i 15 dager.
OCR CuneiForm
Gratis leserprogramvare tekstinformasjon fra bilder. Gjenkjenningsnøyaktigheten er en størrelsesorden lavere enn for det forrige programmet under vurdering. Men hvordan for gratis verktøy, funksjonaliteten er fortsatt utmerket.
Interessant! CuneiForm gjenkjenner blokker med tekst, grafikk og til og med forskjellige tabeller. Dessuten kan selv ulinjede tabeller leses.
For å sikre nøyaktighet er spesielle ordbøker koblet til gjenkjennelsesprosessen, som fyller på vokabularet fra skannede dokumenter.
Fordeler:
- gratis distribusjon;
- bruke ordbøker for å kontrollere riktigheten av teksten;
- skanning av tekst fra fotokopier av dårlig kvalitet.
Feil:
- relativt lav nøyaktighet;
- lite antall språk som støttes.
WinScan2PDF
Det er ikke engang fullverdig program, men et verktøy. Ingen installasjon er nødvendig, og den kjørbare filen veier bare noen få kilobyte. Gjenkjenningsprosessen er ekstremt rask, selv om de resulterende dokumentene lagres utelukkende i PDF-format.
Faktisk utføres hele prosessen ved å trykke på tre knapper: velge kilde, destinasjon og faktisk starte programmet.
Verktøyet er designet for rask batchbehandling av mange filer. For brukerens bekvemmelighet leveres en stor grensesnittspråkpakke.
Fordeler:
- bærbarhet;
- raskt arbeid;
- brukervennlighet.
Feil:
- minste størrelse;
- det eneste utdatafilformatet.
Enkel OCR
Et utmerket lite program for å gjenkjenne tekster fra bilder. Den støtter til og med lesing av manuskripter. Problemet er at russisk verken er inkludert i grensesnittspråkpakken eller i listen over språk som støttes for gjenkjenning.
Men hvis du trenger å skanne engelsk, dansk eller fransk, vil du ikke finne et bedre gratis alternativ.
I sitt omfang gir programmet nøyaktig skriftdekoding, støyfjerning og grafisk bildeekstraksjon. I tillegg har programgrensesnittet innebygd tekstredigerer, nesten identisk med WordPad, noe som øker brukervennligheten til programmet betydelig.
Fordeler:
- nøyaktig tekstgjenkjenning;
- praktisk tekstredigerer;
- fjerne støy fra et bilde.
Feil:
- fullstendig fravær av russisk språk.
Freemore OCR
Programmet lar deg raskt trekke ut tekst og grafikk fra bilder. Programvaren støtter arbeid med flere skannere uten tap av ytelse. Den utpakkede teksten kan lagres i et tekstdokument eller MS Office-dokumentformat.
I tillegg leveres en flersides gjenkjenningsfunksjon.
Freemore OCR distribueres gratis, men grensesnittet er kun på engelsk. Men denne omstendigheten påvirker ikke på noen måte brukervennligheten, fordi kontrollene er organisert på en intuitiv måte.
Fordeler:
- gratis distribusjon;
- evne til å jobbe med flere skannere;
- gjenkjenningsnøyaktigheten er anstendig.
Feil
- Mangel på russisk språk i grensesnittet;
- Behovet for å laste ned den russiske språkpakken for anerkjennelse.
Hvis du har valgt den raske måten å skrive et teoretisk kapittel på, som vi snakket om i avsnitt 2.1., vil du mest sannsynlig ikke klare deg uten å skanne dokumenter. Ellers kan du hoppe over dette punktet og begynne å ta notater om materialer som finnes i biblioteket.
Før du begynner å skanne, må du bestemme deg for hva du vil bruke når du skriver arbeidet ditt. Og for å gjøre dette, må du først se gjennom den tilgjengelige litteraturen og fremheve de nødvendige punktene med en blyant.
Første gang jeg skannet en magasinartikkel for mine første kurs, syntes jeg oppgaven var utrolig vanskelig. Som et resultat av flere timers arbeid med skanneren og FineReader, var utgangen tull som ikke kunne redigeres. Til slutt måtte jeg skrive alt for hånd. For å forhindre at dette skjer med deg, la oss se nærmere på alle de tekniske aspektene ved skanning.
For å skanne trenger vi selvfølgelig en skanner. Du trenger ikke kjøpe den. Du kan for eksempel låne noe av en venn for en stund. Jeg bruker en CanoScan Lide 60 skanner. Selv om det ikke er den mest ny modell, men jeg liker denne kompakte, raske og brukervennlige "enheten". Hvis du låner en skanner, for at den skal fungere, må du først installere driverprogrammet. Drivere og installasjonsinstruksjoner finner du alltid på installasjonsdisk, som følger med enheten eller kan lastes ned fra produsentens nettsted. Etter at du har installert driveren, kobler du skanneren til datamaskinen ved hjelp av tilkoblingsledningen. Nå kan du begynne å skanne direkte.
Men først en liten teori. Du bør vite at skanningsprosessen består av to stadier:
1. Skanner dokumentet direkte. På dette stadiet tar skanneren et bilde av overflaten av dokumentet som skannes og lagrer det resulterende bildet på datamaskinen som en vanlig .jpg .gif-fil eller i et annet format;
2. Dokumentgjenkjenning. Dette er prosessen med å konvertere tekst fra et bilde tatt av en skanner til en vanlig test, som deretter kan lagres i Word og redigeres. Anerkjennelse utføres uten deltakelse av en skanner, ved hjelp av et spesielt program (det mest populære er Adobe FineReader). På denne måten kan du først skanne flere tekstark og lagre dem som et bilde før du konverterer dem til tekst.
Så la oss begynne trinn én - skanning:
– start skannerdriveren: Start - Alle programmer - Canon - ScanGear(Jeg angir drivernavnet for skanneren min). Drivervinduet vises:
– åpne skannerlokket og plasser en bok, et magasin eller en kopi med teksten ned, så jevnt som mulig i forhold til kantene på skannerens arbeidsflate:
Det er veldig viktig her å sørge for at skannerlokket trykker det skannede dokumentet så tett som mulig, og hindrer eksternt lys i å nå arbeidsflaten til skanneren som er i kontakt med dokumentet;
- la oss gjøre det nødvendige innstillinger i skannerdriveren. Det første trinnet er å angi oppløsningen som dokumentet skal skannes med. Oppløsning er en indikator som bestemmer detaljnivået til et objekt ved skanning og bestemmes i punkter per tomme (dpi eller dpi). Jo høyere oppløsning, jo bedre bildekvalitet. Men når du skanner tekstdokumenter, er det ingen vits i å angi maksimal oppløsning, siden dette vil være til null nytte. I tillegg tar det lengre tid å skanne med høyere oppløsninger. Jeg anbefaler å sette oppløsningen mellom 400-500 dpi. Med denne innstillingen er bildene av tilstrekkelig kvalitet for god gjenkjenning, og selve skanneprosessen tar ikke mye tid. Jeg foreslår at du ser på et skjermbilde av skriverinnstillingene mine:
 |
Først må du gå til "Avansert modus". Kilden vil alltid være "Tablett"(flatbedskanner). Det er bedre å stille inn fargemodus "Svart og hvit", fordi vi ikke trenger farger for å skanne tekst, og dette vil redusere størrelsen på utdatabildene. Oppløsningen bør som sagt settes 400 dpi. Utgangsbildestørrelse – nødvendig "A4". Nå kan du trygt trykke på knappen "Skann". Skanneren min er utformet på en slik måte at den først lagrer de skannede bildene i internt minne, og bare når du lukker drivervinduet tilbyr å lagre dem på datamaskinen. Alt jeg trenger å gjøre er å angi stedet der resultatene av arbeidet vil bli lagret.
Du bør ende opp med filer av denne typen:

Når du forstørrer et slikt bilde, skal teksten være godt synlig.
Andre fase – Anerkjennelse mottatte bilder og konvertere dem til tekst. Som jeg allerede sa, vil dette kreve et spesielt program - FineReader. Last ned programmet fra denne linken (32MB). Arkivpassord – nettside. Versjonen jeg foreslår krever ikke installasjon (bærbar). Det vil være mange forskjellige filer i programmappen, men du trenger bare én - FineReader.exe. Dobbeltklikk på denne filen vil starte programmet på datamaskinen din.
Denne versjonen av programmet er ganske gammel. Jeg tok alle skjermbildene nedenfor ved å bruke den. Hvis denne versjonen FineReader det fungerer ikke for deg - velg en nyere.
Vindu FineReader har følgende form:

Etter å ha angitt språket som dokumentene du tidligere skannet ble skrevet ut på, kan du begynne å gjenkjenne. Hvis teksten inneholder to språk samtidig (for eksempel russisk og engelsk), gjør installasjonen deretter.
For å starte gjenkjenningen, klikk på pilen til høyre for den første knappen Skann- og så - Åpne bilde:

Bildevalgsvinduet åpnes. Åpne mappen der du lagret de skannede bildene, klikk CTRL+A(engelsk) på tastaturet og trykk på knappen Åpen.

Etter det til venstre i vinduet FineReader Miniatyrbilder av filene som er lagt til vises, i midten - på dette øyeblikket den valgte skissen er forstørret, under er en enda større økning, og til høyre er gjenkjennelsesresultatet:

For eksempel tok jeg bare to bilder. Den første av dem er uthevet i skjermbildet ovenfor; vi kan gjenkjenne den nå. Som du kan se, ble bildet skannet vertikalt; for å gjenkjenne teksten må bildet først roteres 90 grader. For å gjøre dette, bruk knappene og. Det neste trinnet er å fortelle programmet hvilken del av bildet som må gjenkjennes, og også angi hvilken type data som skal sendes ut: tekst, tabell eller bilde. Det finnes knapper for henholdsvis dette: . Hvis du for eksempel trenger å merke en tekstblokk, venstreklikk på , venstreklikk deretter i øvre venstre hjørne av tekstblokken og mens du holder venstre knapp, dra den til nedre høyre hjørne. For eksempel har jeg forberedt ett bilde for gjenkjenning:

Som du kan se, er alle tekstblokkene i eksemplet ovenfor uthevet i grønt, og bildene er uthevet i rødt. Tabeller utarbeides for gjenkjennelse på samme måte. Det er dette knappen er for. For å gå til neste bilde, venstreklikk på miniatyrbildet til venstre. På denne måten klargjøres alle bilder som oppnås som et resultat av skanning for gjenkjenning. Etter at forberedelsen av bildene er fullført, bør du velge dem alle. For å gjøre dette, venstreklikk på et tomt sted på miniatyrbildepanelet (det kalles Plastpose) og trykk Ctrl+A(engelsk) på tastaturet. Deretter klikker du på knappen og venter til FineReader konverterer bilder til tekst. Etter dette kan du lagre den resulterende teksten i Word ved å bruke knappen, etter å ha klikket på hvilket vindu som åpnes. I den må du velge formatet for lagring - Microsoft Word, og merk også av i boksen for å lagre alle sider:
Etter å ha trykket på knappen OK programmet vil opprette Word-dokument og setter inn tekst fra de gjenkjente sidene i den rekkefølgen de er plassert i miniatyrbildepanelet (Batch). Lagre det mottatte dokumentet umiddelbart i en mappe i filstruktur avhandling og du kan begynne å redigere. Hvordan dette gjøres er beskrevet i min gratis kurs.
Og et siste poeng. Hvis du skannet en avis eller et magasin, er teksten der ofte gitt i form av spalter (som i eksempelet ovenfor). Disse kolonnene i Word må konverteres til én. Velg teksten i kolonner og kjør kommandoen: Format – Kolonner – En – OK. Først etter dette kan du angi Portrettorientering i Sideoppsett, margutfylling, font osv.
Hvordan skanne et dokument og gjenkjenne det i MS Word
Det er praktisk og trygt å lagre skannede dokumenter på datamaskinens harddisk eller ekstern lagringsenhet. Men hvordan gjør du endringer på sider som vanligvis presenteres som et bilde? Vi trenger spesielle programmer, installasjonen og administrasjonen som vi vil beskrive nedenfor.
Hvordan skanne et dokument før redigering?
For å kunne manipulere filen i fremtiden, er det viktig å konvertere den riktig til "bilde" -format, samt ta hensyn til flere enkle, men nyttige nyanser i selve prosessen. For dette:
- Glatt ut alle bretter og folder slik at de ikke vises på skanningen og ikke fører til vanskeligheter med å gjenkjenne bokstaver.
- For enkel referanse, lagre filen i PDF-, JPG- eller TIFF-format.
- PDF-dokumentet kan åpnes og redigeres Adobe-programmet Acrobat (eller noe annet designet for lignende formål).
- Gå til nettstedet til selskapet som opprettet skanneren, eller se etter et proprietært program på den medfølgende disken (ofte har kjente merker egne applikasjoner for å endre skannede sider).
- For senere bruk av filen i MS Office 2003 eller 2007, installer Microsoft-verktøy Skanning av kontordokumenter. Den konverterer den skannede filen automatisk, og konverterer den direkte til tekst (programmet fungerer ikke med nyere versjoner av Office).
- Det anbefales å skanne i svart-hvitt fremfor farger - dette gjør det lettere å analysere teksten.
- TIFF-formatet brukes best for OCR-konverterere, det vil si programmer som utfører optisk gjenkjenning.
Hvordan redigere et skannet dokument - arbeider med OCR-verktøy
Prinsippet for Optical Character Recognition-metoden er å lese tegnene på papir og deretter sammenligne dem med elementer fra din egen database. På denne måten konverteres et solid bilde til redigerbar tekst. Levende eksempler på programmer som takler denne oppgaven er Adobe Acrobat og Evernote. For å gjøre korrigeringer til en eksisterende skanning, åpne den ganske enkelt med en av disse programmene, hele den påfølgende prosessen vil skje automatisk. Når programmet er ferdig med gjenkjenningen, vil det be brukeren om å lagre dokumentet i et av de tilgjengelige formatene.


Hvordan redigere et skannet PDF-dokument
Hvis det skannede dokumentet er lagret i PDF-fil, kan vi enkelt redigere den i Acrobat DC. For dette:
- åpne menyen "Verktøy" -> "Rediger PDF";
- programmet starter redigeringsprosessen, og viser en hintmeny i øverste høyre hjørne;
- ved å klikke på den og velge "Alternativer", kan du spesifisere gjenkjenningsspråket;
- For å gjøre endringer, klikk på en hvilken som helst linje i dokumentet;
- et dokument åpnet for redigering via OCR er ledsaget av et spesielt panel med innstillinger plassert på høyre side av skjermen;
- I delen "Innstillinger", i tillegg til språket, er det også praktisk å velge den viste fonten og merke sidene som må redigeres (alle eller én om gangen).


Det finnes et tilgjengelig alternativ til installerbare konverteringsprogrammer på World Wide Web. Dette er online OCR-er som enkelt kan konvertere det resulterende bildet til et hvilket som helst tekstformat. For eksempel lar nettstedet pdfonline.com deg lage en vanlig MS Word-fil fra et skannet PDF-dokument på noen få minutter.
