Как обрезать отсканированный документ в ворде. Пример того, как отсканированный документ перевести в «Ворд». Интерфейс и доступные задачи
Доброго времени всем!
Я думаю, что те пользователи, кто часто занимается офисной работой (редактирование и подготовка документов, сканирование, их отправка и т.д.), нередко теряют время, копаясь с приведением файлов в презентабельный вид.
Например, отсканировал десяток-другой листов договора, а потом смотришь: а часть листов в нем перевернута (или вообще, какой-то лист лишний ) ... Что делать? Можно заново пересканировать (что и сделает большинство), а можно очень быстро отредактировать документ с помощью спец. программы.
Собственно, в этой статье хочу рассмотреть эту небольшую часть офисной работы. Думаю, многим может пригодиться...
В помощь!
Инструкция по сканированию документов (подключение сканера к ПК, выбор ПО, получение текста со сканов и пр. вопросы) -
Изменение и редактирование PDF-документов
1) Что нужно для работы (выбор ПО)
Буду считать, что документ в формате PDF (который вы хотите отредактировать) у вас уже есть. Теперь необходимо подобрать ПО для его изменения. Для простого и быстрого решения поставленной задачи (на которой остановились в этой статье) подойдет Movavi PDF Редактор .
Movavi PDF Редактор
![]()
Очень компактная и удобная программа, позволяющая быстро редактировать PDF файлы! Отметил бы низкие системные требования данного ПО к железу, благодаря чему, можно даже на "слабеньких" офисных компьютерах открывать и изменять файлы PDF в высоком качестве (в цвете с высоким разрешением).
Особенности:
- есть все базовые функции по редактированию: добавление/удаление страниц, поворот страниц на 90-180 градусов, вставка подписи, картинок, объединение/разбивка документов, конвертирование PDF в картинки (и обратная операция);
- программа открывает и позволяет изменять подавляющее большинство PDF (даже достаточно больших, с высоким разрешением сканирования, что актуально для офиса (многие др. программы могут просто зависнуть));
- низкие системные требования;
- интуитивно понятный интерфейс (кстати, программа полностью на русском языке!);
- совместима с Windows 7, 8, 10 (32/64 bits).
Пожалуй, единственный минус: полная версия программы стоит 600 руб. (впрочем, есть 7 дней для тестирования).
Ниже в статье покажу основные действия, по работе с Movavi PDF редактором.
2) Открытие документа
Установку и запуск редактора не рассматриваю (они стандартны). Для открытия файла PDF - достаточно нажать по одноименной кнопке в первом окне программы. (см. скриншот ниже)
Кстати, отмечу, что программа ведет историю ранее открытых файлов, что со временем позволит быстрее находить документы, с которыми приходится часто работать.


Файл должен открыться в редакторе. Интерфейс программы в общем-то стандартен: слева представлены все странички документа, по центру - сам документ.

Как выглядит открытый документ в Movavi PDF Editor
Теперь можно переходить к редактированию...
3) Поворот страничек на 90-180°
И так, свой документ я открыл не случайно : в нем некоторые странички были отсканированы в горизонтальном положении, а мне нужно всё в вертикальном (прим. : "кривое" специализированное ПО сканера, шедшее вместе с драйверами, автоматически форматирует разметку документа при сохранении в PDF).
Чтобы не выискивать каждую "неправильную" страничку в обычном режиме просмотра, рекомендую перейти в обзор всех страниц (для этого щелкните по кнопке , см. скрин ниже).


Поворот страниц / Кликабельно
Операции поворота страницы выполняются очень быстро: буквально два-три клика и все листы в моем документы стали вертикальной ориентации (см. пример ниже).

Чтобы вернуться в обычный режим работы с документом, нажмите на панельке кнопку "Назад" (см. скрин ниже).

Обратите внимание, что повернуть страницу можно и в меню слева (единственный момент: их не очень удобно "выискивать" здесь...) .

4) Удаление и вставка страниц, картинок
Что касается удаления страницы - то здесь все просто: сначала выделяем нужно страничку в меню слева, затем щелкаем по ней правой кнопкой мышки и в меню выбираем "удалить" (пример ниже).
Также можно использовать клавишу Delete.

Что же касается вставки новых страниц (и картинок) в документ, то здесь несколько интереснее. Сначала необходимо перейти во вкладку .

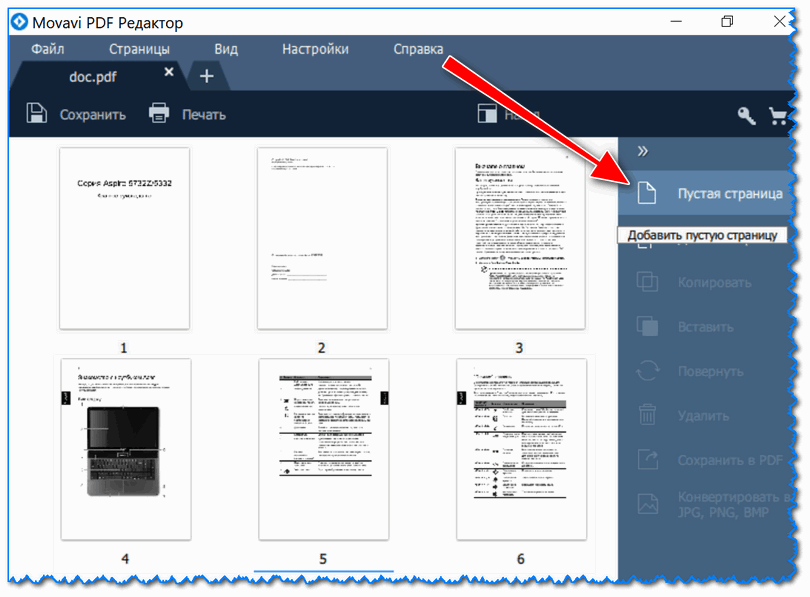
Обратите внимание, у вас в конце документа появится одна пустая страничка. См. скриншот ниже.

Потянув эту пустую страничку мышкой, ее можно перенести в нужную часть документа. Например, я вставил ее на место первой странички (кстати, таким же образом можно отсортировать весь документ, меняя местами странички и перенося их в нужно место) .

Для вставки картинки (изображения) : перейдите на нужную страницу, в верхнем меню выберите опцию . Дальше откроется меню проводника, в котором сможете выбрать нужное.

Например, я в редактируемую инструкцию вставил скриншот о том, как просмотреть характеристики ПК (температуру HDD в частности). Пример ниже.

Картинка добавлена в документ
5) Объединение 2-х документов в 1
Также довольно типичная задача (особенно неприятно, когда один документ состоит из 3-4-х и более PDF файлов). Как их все собрать в один?
Способ #1
Для начала нужно открыть первый документ (страницу) и перейти в режим обзора всех страниц (см. скрин ниже).


Все страницы добавляемого документа встанут в конец открытого документа (извиняюсь за тавтологию). Таким образом, мы фактически "склеиваем" два документа в один.

Последовательно добавляя все "маленькие" документы - вы сможете собрать из них один тот "большой", который хотели изначально...
Способ #2
Этот вариант более прост. После запуска программы, просто нажмите по кнопке (на стартовом окне справа).

Кстати!
Если ваш PDF документ получился слишком большим (а такое также периодически бывает) - то его можно сжать. В одной из своих прошлых статей я приводил несколько вариантов, рекомендую -
На этом пока всё. Дополнения приветствуются...
Программа для оптического распознавания текстов. ABBYY FineReader умеет распознавать текст из отсканированных бумажных документов, PDF-файлов, а также документов, отснятых цифровым фотоаппаратом. Распознанные программой текстовые документы можно в дальнейшем редактировать, используя приложения Microsoft Office. Если нужно, то при распознавании текста будет сохранена вся структура оформления документов. FineReader работает со всеми популярными моделями современных сканеров и многофункциональных устройств (МФУ). Если пользователю нужно отсканировать и распознать большое количество страниц текста, то в программе предусмотрен специальный режим для работы с автоматическими сканерами (сканер с автоподатчиком бумаги). Программа может распознавать текст в файлах следующего формата: PDF, BMP, PCX, DCX, JPEG, JPEG 2000, TIFF, PNG, DjVu, при необходимости будет произведена обработка цифровых изображений для повышения качества оптического распознавания текста (изображение можно обрезать, очистить от ненужных элементов, устранить неточности, искажения строк, осуществить поворот или зеркальное отображение).Программа представляет собой комплексное приложение для работы с текстовыми документами. Её основное назначение – оптическое распознавание символов. Создатель программы - российская кампания ABBYY Software (мировой лидер в области систем распознавания). Приложение осуществляет быстрый и точный перевод отсканированных документов в редактируемый формат, с сохранением всех оригинальных деталей источника. FineReader умеет распознавать PDF файлы, цифровые фотографии и бумажные документы. Программа точно воспроизводит вид оригинального источника, поддерживая распознавание текста на 186 языках и осуществляет прямой экспорт в приложения Microsoft Office.
С помощью приложения решаются такие задачи, как: создание и редактирование электронных документов на основе бумажных источников, перевод в редактируемый формат документов слабого качества, обработка документов со сложной структурой содержания, включающих таблицы, иллюстрации, схемы и т.д., поиск и редактирование текста в любых форматах. По мнению большинства специалистов, программа является лучшей в своей области.
Если говорить о практике использования этой программы в Рунете, то многим пользователям уже давно известна эта программа Файн Ридер (русский перевод названия), основное назначение которой – выполнение так называемого оптического распознавания текста. Если проще – с помощью этой программы любой напечатанный на бумаге текст может быть преобразован в один из электронных форматов. Последняя версия программы отличается не только обновленным и более удобным интерфейсом, но и улучшенной функциональностью.
Фактически, все основные действия могут быть выполнены посредством одного щелчка мыши, которым выбирается одно из предлагаемых при запуске программы действий. Среди них – возможность сканирования документов в формат.doc, конвертация фотографий, сканирование в Excel, сохранение изображений и их сканирование, распознавание изображений и др. С целью повышения удобства использования программы, рабочая область была увеличена, а кнопки, запускающие то или иное действие, находятся теперь на боковой панели.
Чтобы не затруднять пользователя, по умолчанию все файлы, которые он открывает, распознаются автоматически. При необходимости, опытный пользователь может выполнить глубокие настройки функционала FineReader. А работа с изображениями значительно упростилась благодаря новому диалогу. Использование приложения позволяет распознавать документы, составленные с использованием более чем одного языка, преобразовывать файлы PDF, распознавать штрих-коды и вести морфологический поиск. И хотя это далеко не полный перечень его возможностей, уже только это может сподвигнуть многих пользователей установить у себя на постоянной основе Файн Ридер и использовать его по мере необходимости.
И подводя черту под вышесказанным, можно вкратце так обозначить функциональные возможности: эта программа используется для оптического распознавания различных текстовых документов. При распознавании текста, программа сохраняет исходное форматирование и оформление документа (цветной текст, текст на фоне картинок, различные начертания шрифтов, обтекание картинок текстом, таблицы и т.д.). FineReader умеет работать с отсканированными бумажными документами (поддерживается работа практически со всеми популярными моделями сканеров и многофункциональных устройств), с документами, отснятыми цифровыми фотоаппаратами, распознаёт текст и графику из PDF файлов. А также экспортирует результаты оптического распознавания текстов в популярные офисные приложения: Word, Excel, PowerPoint, Lotus Word Pro, Corel WordPerfect, OpenOffice. Распознанный текст можно сохранить в различных форматах: PDF, PDF/A, DOCX, XLSX, RTF, DOC, XLS, CSV, TXT, HTML, Unicode TXT, Word ML, LIT, DBF.
Программы для распознавания текста позволяют конвертировать сфотографированные или отсканированные документы непосредственно в предложения.
Дело в том, что текст на изображении представлен в виде растра, набора точек. Упомянутый софт осуществляет превращение набора точек в полноценный текст, доступный для редактирования и сохранения.
Распознавание букв призвано оптимизировать процесс оцифровки бумажных печатных или рукописных книг, документов.
Такой метод оцифровки на порядки превосходит скорость ручного набора с изображения. Широко применяется при оцифровке библиотек и архивов. Далее рассмотрим пятерку лучших представителей семейства подобных программ.
ABBYY FineReader 10
FineReader безоговорочный лидер среди всех программ, распознающих текст на изображении. В частности, софта, более четко обрабатывающего кириллицу нет. Вообще в активе FineReader 179 языков, текст на которых распознается чрезвычайно успешно.
Единственное обстоятельство, которое может разочаровать пользователей, состоит в том, что программа платная. Бесплатно распространяется только пробная версия на 15 дней. За этот период разрешено сканирование 50-ти страниц.
Дальше за пользование программой придется платить. FineReader легко «кушает» любое более-менее качественное изображение. Источник при этом совершенно неважен. Будь то фотография, скан страницы или любая картинка с буквами.
Достоинства:
- точное распознавание;
- огромное количество языков чтения;
- толерантность к качеству изображения-источника.
Недостаток:
- пробная версия на 15 дней.
OCR CuneiForm
Бесплатная программа для считывания текстовой информации с изображений. Точность распознавания на порядок ниже, чем у предыдущей рассматриваемой программы. Но как для бесплатной утилиты, функционал все-таки на высоте.
Интересно! CuneiForm распознает блоки текста, графические изображения и даже различные таблицы. Более того, считыванию поддаются даже неразлинованные таблицы.
Для обеспечения точности к процессу распознавания подключаются специальные словари, которые пополняют словарный запас из сканируемых документов.
Достоинства:
- бесплатное распространение;
- использование словарей для проверки правильности текста;
- сканирование текста с ксерокопий плохого качества.
Недостатки:
- относительно небольшая точность;
- небольшое количество поддерживаемых языков.
WinScan2PDF
Это даже не полноценная программа, а утилита. Установка не потребуется, а исполнительный файл весит всего в несколько килобайт. Процесс распознавания происходит предельно быстро, правда, полученные в его результате документы сохраняются исключительно в формате PDF.
Фактически весь процесс выполняется при нажатии трех кнопок: выбор источника, места назначения и, собственно, запуска программы.
Утилита предназначена для быстрой пакетной обработки множества файлов. Для удобства пользователей предусмотрен большой языковой пакет интерфейса.
Достоинства:
- портативность;
- быстрая работа;
- простота в использовании.
Недостатки:
- минимальный размер;
- единственный формат файлов на выходе.
SimpleOCR
Отличная небольшая программа для распознавания текстов с изображений. Поддерживает даже чтение рукописей. Беда в том, что русский не входит ни в языковой пакет интерфейса, ни в список поддерживаемых для распознавания языков.
Однако если необходимо отсканировать английский, датский или французский, то лучшего бесплатного варианта не найти.
В своей области программа обеспечивает точную расшифровку шрифтов, удаление шума и извлечение графических изображений. К тому же в интерфейс программы встроен текстовый редактор, практически идентичный WordPad, что значительно повышает удобство использования программы.
Достоинства:
- точное распознавание текста;
- удобный текстовый редактор;
- удаление шума с изображения.
Недостатки:
- полное отсутствие русского языка.
Freemore OCR
Программа позволяет оперативно извлекать текст и графику с изображений. Софт поддерживает работу с несколькими сканерами без потери производительности. Извлеченный текст может быть сохранен в формате текстового документа или документа MS Office.
Кроме того предусмотрена функция многостраничного распознавания.
Распространяется Freemore OCR бесплатно, однако, интерфейс только на английском. Но это обстоятельство никак не влияет на удобство пользования, потому как организованы элементы управления интуитивно понятным образом.
Достоинства:
- бесплатное распространение;
- возможность работы с несколькими сканерами;
- достойна точность распознавания.
Недостатки
- Отсутствие русского языка в интерфейсе;
- Необходимость загрузки русского языкового пакета для распознавания.
Если Вы выбрали быстрый путь написания теоретической главы, о котором мы говорили в параграфе 2.1., вероятней всего Вам не обойтись без сканирования документов. В ином случае, этот пункт можете пропустить и начинать конспектировать материалы найденные в библиотеке .
Перед началом сканирования нужно определиться, что именно Вы хотите использовать при написании работы. А для этого нужно сначала просмотреть имеющуюся литературу и выделить карандашом нужные моменты.
Когда я впервые сканировал статью из журнала для своей первой курсовой, для меня это занятие было невообразимо сложным. В результате нескольких часов работы со сканером и FineReader’ом у меня на выходе вышла бредятина, не поддающаяся редактированию. В итоге пришлось все набирать руками. Чтобы у Вас не случилось подобного, рассмотрим подробнее все технические моменты сканирования.
Для сканирования нам, конечно же, потребуется сканер. Его не обязательно покупать. Можно, например, на время взять на время у товарища. Я пользуюсь сканером CanoScan Lide 60. Это хоть и не самая новая модель, но мне очень нравится этот компактный, быстрый и удобный в работе “девайс”. Если Вы взяли на время сканер, для того чтобы он работал нужно сначала установить программу-драйвер. Драйвера и руководство по установке всегда можно найти на установочном диске, который прилагается к устройству или скачать на сайте у производителя. После установки драйвера, подключите сканнер к компьютеру с помощью соединительного шнура. Теперь можно уже непосредственно приступить к сканированию.
Но сначала немного теории. Вы должны знать, что процесс сканирования состоит из двух этапов:
1. Непосредственно сканирование документа. На этом этапе сканнер как бы фотографирует поверхность сканируемого документа и сохраняет полученное изображение на компьютер в виде обычного файла.jpg .gif или в другом формате;
2. Распознавание документа. Это процесс преобразования текста из изображения сделанного сканером в обычный тест, который потом можно сохранить в Word и редактировать. Распознавание осуществляется без участия сканера, с помощью специальной программы (самая популярная Adobe FineReader). Таким образом, Вы можете сначала отсканировать несколько листов текста и сохранить их в виде изображения и только потом преобразовывать в текст.
Итак, начнем этап первый – сканирование :
– запускаем драйвер сканера: Пуск – Все программы – Canon – ScanGear (название драйвера я указываю для своего сканера). Появится окно драйвера:
– открываем крышку сканера и кладем книгу, журнал или их копию текстом вниз, как можно ровнее по отношению к краям рабочей поверхности сканера:
Здесь очень важно сделать так, чтобы крышка сканера как можно плотнее прижимала сканируемый документ, не допуская попадания внешнего освещения не рабочую поверхность сканера, которая соприкасается с документом;
– выполним необходимые установки в драйвере сканнера. Первым делом нужно установить разрешение, в котором будет отсканирован документ. Разрешение – это показатель, который определяет уровень детализации объекта при сканировании и определяется в точках на дюйм (dpi, или т/д). Чем больше разрешение, тем качественнее получается изображение. Но, при сканировании текстовых документов нет смысла устанавливать максимальное разрешение, поскольку толку от этого будет ноль. Кроме того, сканирование с большим разрешением занимает больше времени. Я рекомендую устанавливать разрешение в пределах 400-500 т/д (dpi). При такой настройке изображения получаются достаточно качественными для хорошего их распознания, а сам процесс сканирования не занимает много времени. Предлагаю посмотреть на скриншот установок моего принтера:
 |
Для начала нужно перейти в “Расширенный режим”. Источником всегда будет “Планшет” (планшетный сканер). Цветной режим лучше установить “Черно-белый” , ведь для сканирования текста нам цвета не нужны, а это уменьшит размер изображений на выходе. Разрешение, как я уже сказал, следует установить 400 т/д . Выходной размер изображения – обязательно “А4” . Теперь можно смело жать на кнопку “Сканировать” . Мой сканер устроен таким образом, что сначала запоминает отсканированные изображения во внутренней памяти, и только при закрытии окна драйвера предлагает сохранить их на компьютер. Мне остается только указать место, куда будут сохранены результаты работы.
У вас должны получаться файлы такого типа:

При увеличении такого изображения должен быть отчетливо виден текст.
Второй этап – распознание полученных изображений и их преобразование в текст. Как я уже говорил, для этого понадобится специальная программа – FineReader . Скачайте программу по этой ссылке (32Мб) . Пароль к архиву – сайт . Предложенная мной версия не требует установки (portable). В папке с программой будет множество разных файлов, но Вам нужен только один – FineReader.exe . Двойной клик на этом файле запустит программу на Вашем компьютере.
Эта версия программы достаточно старая. Все скриншоты ниже я делал используя именно её. Если эта версия FineReader у вас не запускается - выберите более новую .
Окно FineReader имеет следующий вид:

После установки языка, на котором напечатаны отсканированные Вами ранее документы, можно начинать распознание. Если в тексте присутствует сразу два языка (например, русский и английский) установку сделайте соответственно.
Чтобы начать распознание нажмите на стрелку справа от первой кнопки Сканировать – а затем – Открыть изображение:

Откроется окно выбора изображений. Откройте папку в которую Вы сохранили отсканированные изображения, нажмите CTRL + A (английское) на клавиатуре и нажмите на кнопку Открыть .

После этого слева в окне FineReader’а появятся эскизы добавленных файлов, по центру – на данный момент выделенный эскиз в увеличенном виде, снизу – еще большее увеличение, а справа результат распознания:

Для примера я взял всего два изображения. На скриншоте выше выделено первое из них, его сейчас и распознаем. Как видите, изображение отсканировано вертикально, чтобы распознать текст снимок нужно сначала развернуть на 90 градусов. Для этого воспользуемся кнопками и . Следующим шагом нужно указать программе, какую именно часть изображения нужно распознать, а также задать тип данных, которые должны получиться на выходе текст, таблица или изображение. Для этого существуют кнопки, соответственно: . Например, если нужно отметить текстовый блок, нажимаем левой кнопкой на , после этого нажимаем левой кнопкой мышки в левом верхнем углу текстового блока и, удерживая левую кнопку, перетягиваем в правый нижний угол. Для примера я полностью подготовил к распознанию одно изображение:

Как видите, все текстовые блоки в примере выше выделены зеленым, а рисунки – красным. Таблицы подготавливаются к распознанию аналогично. Для этого предназначена кнопка . Для того, чтобы перейти к следующему снимку, кликните левой кнопкой мыши на его эскизе слева. Таким образом подготавливаются к распознанию все полученные в результате сканирования изображения. После того, как подготовка изображений завершена, следует выделить их все. Для этого кликните левой кнопкой в пустом месте на панели эскизов (она называется Пакет ) и нажмите Ctrl+A (английское) на клавиатуре. Далее кликните на кнопку и подождите пока FineReader преобразует изображения в текст. После этого можно сохранять полученный текст в Word с помощью кнопки , после нажатия на которую откроется окно . В нем необходимо выбрать формат для сохранения – Microsoft Word, а также поставить отметку чтобы сохранились все страницы:
После нажатия кнопки ОК программа создаст документ Word и вставит в него текст из распознанных страниц в том порядке, в котором они находятся на панели эскизов (Пакет). Полученный документ сразу же сохраните в папку в файловой структуре дипломной работы и можете приступать к редактированию. Как это делается, описано в моем бесплатном курсе .
И последний момент. Эсли Вы сканировали газету или журнал, текст там часто дается в виде колонок (как в рассматриваемом примере выше). Эти колонки в Ворде нужно преобразовать в одну. Выделите текст в виде колонок и выполните команду: Формат – Колонки – Одна – ОК . Только после этого можно ставить Книжную ориентацию в Параметрах страницы, отступы полей, шрифт и т.д.
Как отсканировать документ и распознать его в MS Word
Хранить отсканированные документы на жестком диске компьютера или внешнем носителе удобно и безопасно. Однако как внести изменения в страницы, обычно представленные в виде изображения? Нам понадобятся специальные программы, об установке и управлении которыми мы расскажем ниже.
Как отсканировать документ перед редактированием?
Чтобы успешно манипулировать файлом в дальнейшем, важно правильно перевести его в формат “картинки”, а также учесть несколько простых, но полезных нюансов в самом процессе. Для этого:
- Разгладьте все заломы и складки, чтобы они не отобразились на скане и не привели к трудностям в распознавании букв.
- Для удобства обращения сохраните файл в формате PDF, JPG или TIFF.
- PDF-документ можно будет открыть и редактировать программой Adobe Acrobat (или любой другой, предназначенной для подобных целей).
- Зайдите на сайт компании-создателя сканера, либо поищите фирменную программу на прилагавшемся диске (часто известные бренды имеют собственные приложения для изменения отсканированных страниц).
- Для последующего использования файла в MS Office 2003 или 2007, установите утилиту Microsoft Office Document Scanning. Она производит конвертацию сканируемого файла автоматически, переводя его сразу в текст (программа не работает с более “свежими” версиями Офиса).
- Рекомендуется сканировать в черно-белой гамме, а не в цветной – это упрощает анализ текста.
- TIFF формат лучше всего применять для OCR конвертеров, то есть программ, производящих оптическое распознавание.
Как отредактировать отсканированный документ – работа с OCR-утилитами
Принцип метода Optical Character Recognition - считывание имеющихся на бумаге символов, их последующее сравнение с элементами из собственной базы данных. Таким образом происходит преобразование сплошной картинки в редактируемый текст. Яркие примеры программ, справляющихся с данной задачей – Adobe Acrobat и Evernote. Чтобы внести исправления в имеющийся скан, просто откройте его одним из таких приложений, весь последующий процесс произойдет автоматически. Когда программа закончит распознавание, то предложит пользователю сохранить документ в одном из доступных форматов.


Как отредактировать отсканированный документ PDF
Если отсканированный документ сохранен в файле PDF, мы с легкостью сможем отредактировать его в программе Acrobat DC. Для этого:
- открываем меню “Инструменты” -> “Редактировать PDF”;
- программа запускает процесс редактирования, показывая меню подсказок в правом углу сверху;
- щелкнув на ней и выбрав “Параметры”, можно указать язык распознавания;
- что внести изменения, просто щелкните на любой строке документа;
- документ, открытый для редактирования через OCR, сопровождается особой панелью с настройками, размещенной в правой стороне экрана;
- в разделе “Настройки”, кроме языка, также удобно выбирать отображаемый шрифт, отмечать страницы, которые необходимо редактировать (все или по одной).


Во всемирной сети существует доступная альтернатива устанавливаемым программам-конвертерам. Это онлайновые OCR, которые без труда переведут полученное изображение в любой текстовый формат. К примеру, сайт pdfonline.com позволит за несколько минут из отсканированного PDF-документа сделать обычный файл MS Word.
